Table of Contents
A node is a single instance of SymmetricDS. It can be thought of as a proxy for a database which manages the synchronization of data to and/or from its database. For our example retail application, the following would be SymmetricDS nodes:
Each node of SymmetricDS can be either embedded in another application, run stand-alone, or even run in the background as a service. If desired, nodes can be clustered to help disperse load if they send and/or receive large volumes of data to or from a large number of nodes.
Individual nodes are easy to identify when planning your implementation. If a database exists in your domain that needs to send or receive data, there needs to be a corresponding SymmetricDS instance (a node) responsible for managing the synchronization for that database.
Nodes are defined in the NODE table. Two other tables play a direct role in defining a node, as well The first is NODE_IDENTITY . The only row in this table is inserted in the database when the node first registers with a parent node. In the case of a root node, the row is entered by the user. The row is used by a node instance to determine its node identity.
The following SQL statements set up a top-level registration server as a node identified as "00000" in the "corp" node group.
insert into SYM_NODE (node_id,
node_group_id, external_id, sync_enabled) values ('00000', 'corp',
'00000', 1); insert into SYM_NODE_IDENTITY values ('00000');
The second table, NODE_SECURITY has rows created for each child node that registers with the node, assuming auto-registration is enabled. If auto registration is not enabled, you must create a row in NODE and NODE_SECURITY for the node to be able to register. You can also, with this table, manually cause a node to re-register or do a re-initial load by setting the corresponding columns in the table itself.
Node registration is the act of setting up a new
NODE
and
NODE_SECURITY
so that when the new node is brought online it is allowed to join the
system. Nodes are only allowed to register if rows exist for the node
and the
registration_enabled
flag is set to 1. If the
auto.registration
SymmetricDS property is set to true, then when a node attempts to
register, if registration has not already occurred, the node will
automatically be registered.
SymmetricDS allows you to have multiple nodes with the same
external_id
. Out of the box, openRegistration will open a new registration if a
registration already exists for a node with the same external_id. A new
registration means a new node with a new
node_id
and the same
external_id
will be created. If you want to re-register the same node you can use
the
reOpenRegistration()
JMX method which takes a
node_id
as an argument.
An initial load is the process of seeding tables at a target node with data from its parent node. When a node connects and data is extracted, after it is registered and if an initial load was requested, each table that is configured to synchronize to the target node group will be given a reload event in the order defined by the end user. A SQL statement is run against each table to get the data load that will be streamed to the target node. The selected data is filtered through the configured router for the table being loaded. If the data set is going to be large, then SQL criteria can optionally be provided to pare down the data that is selected out of the database.
An initial load cannot occur until after a node is registered. An
initial load is requested by setting the
initial_load_enabled
column on
NODE_SECURITY
to
1
on the row for the target node in the parent node's database. You can
configure SymmetricDS to automatically perform an initial load when a
node registers by setting the parameter
auto.reload
to true. Regardless of how the initial load is initiated, the next time
the source node routes data, reload batches will be inserted. At the
same time reload batches are inserted, all previously pending batches
for the node are marked as successfully sent.
Note that if the parent node that a node is registering with is
not
a registration server node (as can happen with a registration redirect
or certain non-tree structure node configurations) the parent node's
NODE_SECURITY
entry must exist at the parent node and have a non-null value for column
initial_load_time
. Nodes can't be registered to non-registration-server nodes without
this value being set one way or another (i.e., manually, or as a result
of an initial load occurring at the parent node).
SymmetricDS recognizes that an initial load has completed when the
initial_load_time
column on the target node is set to a non-null value.
An initial load is accomplished by inserting reload batches in a defined
order according to the
initial_load_order
column on
TRIGGER_ROUTER
. If the
initial_load_order
column contains a negative value the associated table will
NOT
be loaded. If the
initial_load_order
column contains the same value for multiple tables, SymmetricDS will
attempt to order the tables according to foreign key constraints. If
there are cyclical constraints, then foreign keys might need to be
turned off or the initial load will need to be manually configured based
on knowledge of how the data is structured.
Initial load data is always queried from the source database table. All data is passed through the configured router to filter out data that might not be targeted at a node.
There are several parameters that can be used to specify what, if anything, should be done to the table on the target database just prior to loading the data. Note that the parameters below specify the desired behavior for all tables in the initial load, not just one.
initial.load.delete.first /
initial.load.delete.first.sql
By default, an initial load will not delete existing rows from a target
table before loading the data. If a delete is desired, the parameter
initial.load.delete.first
can be set to true. If true, the command found in
initial.load.delete.first.sql
will be run on each table prior to loading the data. The default value
for
initial.load.delete.first.sql
is
delete from %s
, but could be changed if needed. Note that additional reload batches
are created, in the correct order, to achieve the delete.
initial.load.create.first
By default, an initial load will not create the table on the target if
it doesn't alleady exist. If the desired behavior is to create the table
on the target if it is not present, set the parameter
intial.load.create.first
to true. SymmetricDS will attempt to create the table and indexes on the
target database before doing the initial load. (Additional batches are
created to represent the table schema).
An efficient way to select a subset of data from a table for an initial
load is to provide an
initial_load_select
clause on
TRIGGER_ROUTER
. This clause, if present, is applied as a
where
clause to the SQL used to select the data to be loaded. The clause may
use "t" as an alias for the table being loaded, if needed. The
$(externalId)
token can be used for subsetting the data in the where clause.
In cases where routing is done using a feature like
Section 3.6.4, “Subselect Router”
, an
initial_load_select
clause matching the subselect's criteria would be a more efficient
approach. Some routers will check to see if the
initial_load_select
clause is provided, and they will
not
execute assuming that the more optimal path is using the
initial_load_select
statement.
One example of the use of an initial load select would be if you wished
to only load data created more recently than the start of year 2011.
Say, for example, the column
created_time
contains the creation date. Your
initial_load_select
would read
created_time > ts {'2011-01-01 00:00:00.0000'}
(using whatever timestamp format works for your database). This then
gets applied as a
where
clause when selecting data from the table.
When providing an
initial_load_select
be sure to test out the criteria against production data in a query
browser. Do an explain plan to make sure you are properly using indexes.
By default, all data for a given table will be initial loaded in a single batch, regardless of the max batch size parameter on the reload channel. That is, for a table with one million rows, all rows for that table will be initial loaded and sent to the destination node in a single batch. For large tables, this can result in a batch that can take a long time to extract and load.
Initial loads for a table can be broken into multiple batches by specifying
initial.load.use.extract.job.enabled to true. This parameter allows
SymmetricDS to pre-extract initial load batches versus having them extracted when
the batch is pulled or pushed. When using this parameter, there are two ways to tell
SymmetricDS the number of batches to create for a given table. The first is to specify
a positive integer in the initial_load_batch_count column on
TRIGGER_ROUTER. This
number will dictate the number of batches created for the initial load of the given table.
The second way is to specify 0 for initial_load_batch_count on
TRIGGER_ROUTER and
specify a max_batch_size on the reload channel in CHANNEL.
When 0 is specified for
initial_load_batch_count, SymmetricDS will execute a count(*) query on the table during
the extract process and create N batches based on the total number of records found
in the table divided by the max_batch_size on the reload channel.
The default behavior for initial loads is to load data from the
registration server or parent node, to a client node. Occasionally,
there may be need to do a one-time intial load of data in the opposite
or "reverse" direction, namely from a client node to the registration
node. To achieve this, set the parameter
auto.reload.reverse
to be true,
but only for the specific node group representing
the client nodes
. This will cause a onetime reverse load of data, for tables configured
with non-negative initial load orders, to be batched at the point when
registration of the client node is occurring. These batches are then
sent to the parent or registration node. This capability might be
needed, for example, if there is data already present in the client that
doesn't exist in the parent but needs to.
There may be times where you find you need to re-send or re-synchronize data when the change itself was not captured. This could be needed, for example, if the data changes occurred prior to SymmetricDS placing triggers on the data tables themselves, or if the data at the destination was accidentally deleted, or for some other reason. Two approaches are commonly taken to re-send the data, both of which are discussed below.
Be careful when re-sending data using either of these two techniques. Be sure you are only sending the rows you intend to send and, more importantly, be sure to re-send the data in a way that won't cause foreign key constraint issues at the destination. In other words, if more than one table is involved, be sure to send any tables which are referred to by other tables by foreign keys first. Otherwise, the channel's synchronization will block because SymmetricDS is unable to insert or update the row because the foreign key relationship refers to a non-existent row in the destination!
One possible approach would be to "touch" the rows in individual tables that need re-sent. By "touch", we mean to alter the row data in such a way that SymmetricDS detects a data change and therefore includes the data change in the batching and synchronizing steps. Note that you have to change the data in some meaningful way (e.g., update a time stamp); setting a column to its current value is not sufficient (by default, if there's not an actual data value change SymmetricDS won't treat the change as something which needs synched.
A second approach would be to take advantage of SymmetricDS built-in functionality by simulating a partial "initial load" of the data. The approach is to manually create "reload" events in DATA for the necessary tables, thereby resending the desired rows for the given tables. Again, foreign key constraints must be kept in mind when creating these reload events. These reload events are created in the source database itself, and the necessary table, trigger-router combination, and channel are included to indicate the direction of synchronization.
To create a reload event, you create a DATA row, using:
Let's say we need to re-send a particular sales transaction from the store to corp over again because we lost the data in corp due to
an overzealous delete. For the tutorial, all transaction-related tables start with sale_,
use the sale_transaction channel, and are routed using the store_corp_identity
router. In addition, the trigger-routers have been set up with an initial load order based on the necessary
foreign key relationships (i.e., transaction tables which are "parents" have a lower initial load order than those of their
"children"). An insert statement that would create the necessary "reload" events (three in this case, one for each table) would be as follows
(where MISSING_ID is changed to the needed transaction id):
insert into sym_data ( select null, t.source_table_name, 'R', 'tran_id=''MISSING-ID''', null, null, h.trigger_hist_id, t.channel_id, '1', null, null, current_timestamp from sym_trigger t inner join sym_trigger_router tr on t.trigger_id=tr.trigger_id inner join sym_trigger_hist h on h.trigger_hist_id=(select max(trigger_hist_id) from sym_trigger_hist where trigger_id=t.trigger_id) where channel_id='sale_transaction' and tr.router_id like 'store_corp_identity' and (t.source_table_name like 'sale_%') order by tr.initial_load_order asc);
This insert statement generates three rows, one for each configured sale table. It uses the most recent trigger history id for the corresponding table. It takes advantage of the initial load order for each trigger-router to create the three rows in the correct order (the order corresponding to the order in which the tables would have been initial loaded).
Work done by SymmetricDS is initiated by jobs. Jobs are tasks that are
started and scheduled by a job manager. Jobs are enabled by the
start.{name}.job
property. Most jobs are enabled by default. The frequency at which a job
runs in controlled by one of two properties:
job.{name}.period.time.ms
or
job.{name}.cron
. If a valid cron property exists in the configuration, then it will be
used to schedule the job. Otherwise, the job manager will attempt to use
the period.time.ms property.
The frequency of jobs can be configured in either the engines properties file or in PARAMETER . When managed in PARAMETER the frequency properties can be changed in the registration server and when the updated settings sync to the nodes in the system the job manager will restart the jobs at the new frequency settings.
SymmetricDS utilizes Spring's CRON support, which includes seconds as
the first parameter. This differs from the typical Unix-based
implementation, where the first parameter is usually minutes. For
example,
*/15 * * * * *
means every 15 seconds, not every 15 minutes. See
Spring's
documentation
for more details.
Some jobs cannot be run in parallel against a single node. When running
on a cluster these jobs use the
LOCK
table to get an exclusive semaphore to run the job. In order to use this
table the
cluster.lock.enabled
must be set to true.
The three main jobs in SymmetricDS are the route, push and pull jobs. The route job decides what captured data changes should be sent to which nodes. It also decides what captured data changes should be transported and loaded together in a batch. The push and pull jobs are responsible for initiating HTTP communication with linked nodes to push or pull data changes that have been routed.
After data is captured in the DATA table, it is routed to specific nodes in batches by the Route Job . It is a single background task that inserts into DATA_EVENT and OUTGOING_BATCH .
The job processes each enabled channel, one at a time, collecting a list
of data ids from
DATA
which have not been routed (see
Section 4.3.1.1, “Data Gaps”
for much more detail about this step), up to a limit specified by the
channel configuration (
max_data_to_route
, on
CHANNEL
). The data is then batched based on the
batch_algorithm
defined for the channel. Note that, for the
default
and
transactional
algorithm, there may actually be more than
max_data_to_route
included depending on the transaction boundaries. The mapping of data to
specific nodes, organized into batches, is then recorded in
OUTGOING_BATCH
with a status of "RT" in each case (representing the fact that the Route
Job is still running). Once the routing algorithms and batching are
completed, the batches are organized with their corresponding data ids
and saved in
DATA_EVENT
. Once
DATA_EVENT
is updated, the rows in
OUTGOING_BATCH
are updated to a status of New "NE".
The route job will respect the
max_batch_size
on
OUTGOING_BATCH
. If the max batch size is reached before the end of a database
tranaction and the batch algorithm is set to something other than
nontransactional
the batch may exceed the specified max size.
The route job delegates to a router defined by the
router_type
and configured by the
router_expression
in the
ROUTER
table. Each router that has a
source_node_group_id
that matches the current node's source node group id and is linked to
the
TRIGGER
that captured the data gets an opportunity to choose a list of nodes the
data should be sent to. Data can only be routed to nodes that belong to
the router's
target_node_group_id
.
On the surface, the first Route Job step of collecting unrouted data ids seems simple: assign sequential data ids for each data row as it's inserted and keep track of which data id was last routed and start from there. The difficulty arises, however, due to the fact that there can be multiple transactions inserting into DATA simultaneously. As such, a given section of rows in the DATA table may actually contain "gaps" in the data ids when the Route Job is executing. Most of these gaps are only temporarily and fill in at some point after routing and need to be picked up with the next run of the Route Job. Thus, the Route Job needs to remember to route the filled-in gaps. Worse yet, some of these gaps are actually permanent and result from a transaction that is rolled back for some reason. In this case, the Route Job must continue to watch for the gap to fill in and, at some point, eventually gives up and assumes the gap is permanent and can be skipped. All of this must be done in some fashion that guarantees that gaps are routed when they fill in while also keeping routing as efficient as possible.
SymmetricDS handles the issue of data gaps by making use of a table,
DATA_GAP
, to record gaps found in the data ids. In fact, this table completely
defines the entire range of data tha can be routed at any point in time.
For a brand new instance of SymmetricDS, this table is empty and
SymmetricDS creates a gap starting from data id of zero and ending with
a very large number (defined by
routing.largest.gap.size
). At the start of a Route Job, the list of valid gaps (gaps with status
of 'GP') is collected, and each gap is evaluated in turn. If a gap is
sufficiently old (as defined by
routing.stale.dataid.gap.time.ms
, the gap is marked as skipped (status of 'SK') and will no longer be
evaluated in future Route Jobs (note that the 'last' gap (the one with
the highest starting data id) is never skipped). If not skipped, then
DATA_EVENT
is searched for data ids present in the gap. If one or more data ids is
found in
DATA_EVENT
, then the current gap is marked with a status of OK, and new gap(s) are
created to represent the data ids still missing in the gap's range. This
process is done for all gaps. If the very last gap contained data, a new
gap starting from the highest data id and ending at (highest data id +
routing.largest.gap.size
) is then created. This process has resulted in an updated list of gaps
which may contain new data to be routed.
After database-change data is routed, it awaits transport to the target nodes. Transport
can occur when a client node is configured to pull data or when the host
node is configured to push data. These events are controlled by the
push
and the
pull jobs
. When the
start.pull.job
SymmetricDS property is set to
true
, the frequency that data is pulled is controlled by the
job.pull.period.time.ms
. When the
start.push.job
SymmetricDS property is set to
true
, the frequency that data is pushed is controlled by the
job.push.period.time.ms
.
Data is extracted by channel from the source database's
DATA
table at an interval controlled by the
extract_period_millis
column on the
CHANNEL
table. The
last_extract_time
is always recorded, by channel, on the
NODE_CHANNEL_CTL
table for the host node's id. When the Pull and Push Job run, if the
extract period has not passed according to the last extract time, then
the channel will be skipped for this run. If the
extract_period_millis
is set to zero, data extraction will happen every time the jobs run.
The maximum number of batches to extract per synchronization is
controlled by
max_batch_to_send
on the
CHANNEL
table. There is also a setting that controls the max number of bytes to
send in one synchronization. If SymmetricDS has extracted the more than
the number of bytes configured by the
transport.max.bytes.to.sync
parameter, then it will finish extracting the current batch and finish
synchronization so the client has a chance to process and acknowlege the
"big" batch. This may happen before the configured max number of batches
has been reached.
Both the push and pull jobs can be configured to push and pull multiple
nodes in parallel. In order to take advantage of this the
pull.thread.per.server.count
or
push.thread.per.server.count
should be adjusted (from their default value of 10) to the number to the
number of concurrent push/pulls you want to occur per period on each
SymmetricDS instance. Push and pull activity is recorded in the
NODE_COMMUNICATION
table. This table is also used to lock push and pull activity across
multiple servers in a cluster.
SymmetricDS also provides the ability to configure windows of time when
synchronization is allowed. This is done using the
NODE_GROUP_CHANNEL_WND
table. A list of allowed time windows can be specified for a node group
and a channel. If one or more windows exist, then data will only be
extracted and transported if the time of day falls within the window of
time specified. The configured times are always for the target node's
local time. If the
start_time
is greater than the
end_time
, then the window crosses over to the next day.
All data loading may be disabled by setting the
dataloader.enable
property to false. This has the effect of not allowing incoming
synchronizations, while allowing outgoing synchronizations. All data
extractions may be disabled by setting the
dataextractor.enable
property to false. These properties can be controlled by inserting into
the root server's
PARAMETER
table. These properties affect every channel with the exception of the
'config' channel.
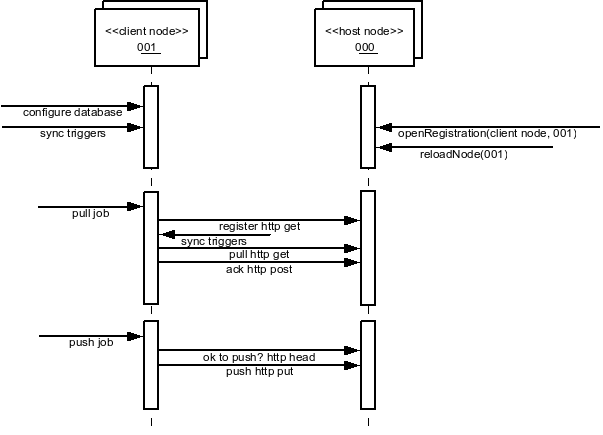
Node communication over HTTP is represented in the following figure.
The File Sync Push and Pull jobs (introduced in version 3.5) are responsible for synchronizing file changes.
These jobs work with batches on the filesync channel and create ZIP files of changed files
to be sent and applied on other nodes.
The parameters job.file.sync.push.period.time.ms and job.file.sync.pull.period.time.ms
control how often the jobs runs, which default to every 60 seconds.
See also Section 4.3, “Jobs” and Section 3.5.2, “Operation”.
The File System Tracker job (introduced in version 3.5) is responsible for monitoring and
recording the events of files being created, modified, or deleted.
It records the current state of files to the FILE_SNAPSHOT table.
The parameter job.file.sync.tracker.cron controls how often the job runs,
which defaults to every 5 minutes.
See also Section 4.3, “Jobs” and Section 3.5, “File Triggers / File Synchronization”.
SymmetricDS examines the current configuration, corresponding database triggers, and the underlying tables to determine if database triggers need created or updated. The change activity is recorded on the TRIGGER_HIST table with a reason for the change. The following reasons for a change are possible:
N - New trigger that has not been created before
S - Schema changes in the table were detected
C - Configuration changes in Trigger
T - Trigger was missing
A configuration entry in Trigger without any history in Trigger Hist
results in a new trigger being created (N). The Trigger Hist stores a
hash of the underlying table, so any alteration to the table causes the
trigger to be rebuilt (S). When the
last_update_time
is changed on the Trigger entry, the configuration change causes the
trigger to be rebuilt (C). If an entry in Trigger Hist is missing the
corresponding database trigger, the trigger is created (T).
The process of examining triggers and rebuilding them is automatically
run during startup and each night by the SyncTriggersJob. The user can
also manually run the process at any time by invoking the
syncTriggers()
method over JMX.
Purging is the act of cleaning up captured data that is no longer needed in SymmetricDS's runtime tables. Data is purged through delete statements by the Purge Job . Only data that has been successfully synchronized will be purged. Purged tables include:
The purge job is enabled by the
start.purge.job
SymmetricDS property. The timing of the three purge jobs (incoming,
outgoing, and data gaps) is controlled by a cron expression as specified
by the following properties:
job.purge.outgoing.cron
,
job.purge.incoming.cron
, and
job.purge.datagaps.cron
. The default is
0 0 0 * * *
, or once per day at midnight.
Two retention period properties indicate how much history SymmetricDS
will retain before purging. The
purge.retention.minutes
property indicates the period of history to keep for synchronization
tables. The default value is 5 days. The
statistic.retention.minutes
property indicates the period of history to keep for statistics. The
default value is also 5 days.
The purge properties should be adjusted according to how much data is flowing through the system and the amount of storage space the database has. For an initial deployment it is recommended that the purge properties be kept at the defaults, since it is often helpful to be able to look at the captured data in order to triage problems and profile the synchronization patterns. When scaling up to more nodes, it is recomended that the purge parameters be scaled back to 24 hours or less.
By design, whenever SymmetricDS encounters an issue with a synchronization, the batch containing the error is marked as being in an error state, and all subsequent batches for that particular channel to that particular node are held and not synchronized until the error batch is resolved. SymmetricDS will retry the batch in error until the situation creating the error is resolved (or the data for the batch itself is changed).
Analyzing and resolving issues can take place on the outgoing or incoming side. The techniques for analysis are slightly different in the two cases, however, due to the fact that the node with outgoing batch data also has the data and data events associated with the batch in the database. On the incoming node, however, all that is available is the incoming batch header and data present in an incoming error table.
The first step in analyzing the cause of a failed batch is to locate information about the data in the batch, starting with OUTGOING_BATCH To locate batches in error, use:
select * from sym_outgoing_batch where error_flag=1;
Several useful pieces of information are available from this query:
BATCH_ID.
NODE_ID.
CHANNEL_ID.
All subsequent batches on this channel to this node will be held until the error condition is resolved.
FAILED_DATA_ID.
SQL_MESSAGE,
SQL_STATE, and SQL_CODE, respectively.
error_flag on the batch table, as shown above, is more reliable than using the
status column. The status column can change from 'ER' to a different status temporarily as
the batch is retried.
To get a full picture of the batch, you can query for information representing the complete list of all data changes associated with the failed batch by joining DATA and DATA_EVENT, such as:
select * from sym_data where data_id in (select data_id from sym_data_event where batch_id='XXXXXX');
where XXXXXX is the batch id of the failing batch.
This query returns a wealth of information about each data change in a batch, including:
TABLE_NAME,EVENT_TYPE,
ROW_DATA and
OLD_DATA, respectively.
PK_DATA
More importantly, if you narrow your query to just the failed data id you can determine the exact data change that is causing the failure:
select * from sym_data where data_id in (select failed_data_id from sym_outgoing_batch where batch_id='XXXXX' and node_id='YYYYY');
where XXXXXX is the batch id and YYYYY is the node id of the batch that is failing.
The queries above usually yield enough information to be able to determine why a particular batch is failing. Common reasons a batch might be failing include:
Once you have decided upon the cause of the issue, you'll have to decide the best course of action to fix the issue. If, for example, the problem is due to a database schema mismatch, one possible solution would be to alter the destination database in such a way that the SQL error no longer occurs. Whatever approach you take to remedy the issue, once you have made the change, on the next push or pull SymmetricDS will retry the batch and the channel's data will start flowing again.
If you have instead decided that the batch itself is wrong, or does not need synchronized, or you wish to remove a particular data change from a batch, you do have the option of changing the data associated with the batch directly.
Now that you've read the warning, if you still want to change the batch data itself, you do have several options, including:
update sym_outgoing_batch set status='OK' where batch_id='XXXXXX'where XXXXXX is the failing batch. On the next pull or push, SymmetricDS will skip this batch since it now thinks the batch has already been synchronized. Note that you can still distinguish between successful batches and ones that you've artificially marked as 'OK', since the
error_flag column on
the failed batch will still be set to '1' (in error).
delete from sym_data_event where batch_id='XXXXXX' and data_id='YYYYYY'where XXXXXX is the failing batch and YYYYYY is the data id to longer be included in the batch.
Analysis using an incoming batch is different than that of outgoing batches. For incoming batches, you will rely on two tables, INCOMING_BATCH and INCOMING_ERROR. The first step in analyzing the cause of an incoming failed batch is to locate information about the batch, starting with INCOMING_BATCH To locate batches in error, use:
select * from sym_incoming_batch where error_flag=1;
Several useful pieces of information are available from this query:
BATCH_ID. Note that this is the batch number of the
outgoing batch on the outgoing node.
NODE_ID.
CHANNEL_ID.
All subsequent batches on this channel from this node will be held until the error condition is resolved.
FAILED_DATA_ID.
SQL_MESSAGE,
SQL_STATE, and SQL_CODE, respectively.
For incoming batches, we do not have data and data event entries in the database we can query. We do, however, have a table, INCOMING_ERROR, which provides some information about the batch.
select * from sym_incoming_error where batch_id='XXXXXX' and node_id='YYYYY';
where XXXXXX is the batch id and YYYYY is the node id of the failing batch.
This query returns a wealth of information about each data change in a batch, including:
TARGET_TABLE_NAME,EVENT_TYPE,
ROW_DATA and
OLD_DATA, respectively,COLUMN_NAMES,PK_COLUMN_NAMES,
For batches in error, from the incoming side you'll also have to decide the best course of action to fix the issue.
Incoming batch errors that are in conflict can by fixed by taking advantage of two columns in INCOMING_ERROR which are examined each time
batches are processed. The first column, resolve_data if filled in will be used in place of row_data.
The second column, resolve_ignore if set will cause this particular data item to be ignored and batch processing to continue. This is the same
two columns used when a manual conflict resolution strategy is chosen, as discussed in Section 3.7.1, “Conflict Detection and Resolution”.
SymmetricDS creates temporary extraction and data load files with the CSV payload of a synchronization when
the value of the stream.to.file.threshold.bytes SymmetricDS property has been reached. Before reaching the threshold, files
are streamed to/from memory. The default threshold value is 32,767 bytes. This feature may be turned off by setting the stream.to.file.enabled
property to false.
SymmetricDS creates these temporary files in the directory specified by the java.io.tmpdir Java System property.
The location of the temporary directory may be changed by setting the Java System property passed into the Java program at startup. For example,
-Djava.io.tmpdir=/home/.symmetricds/tmp
The standalone SymmetricDS installation uses Log4J for logging. The configuration file is conf/log4j.xml.
The log4j.xml file has hints as to what logging can be enabled for useful, finer-grained logging.
There is a command line option to turn on preconfigured debugging levels. When the --debug option is used the conf/debug-log4j.xml is used instead of log4j.xml.
SymmetricDS proxies all of its logging through SLF4J. When deploying to an application server or if Log4J is not being leveraged, then the general rules for for SLF4J logging apply.