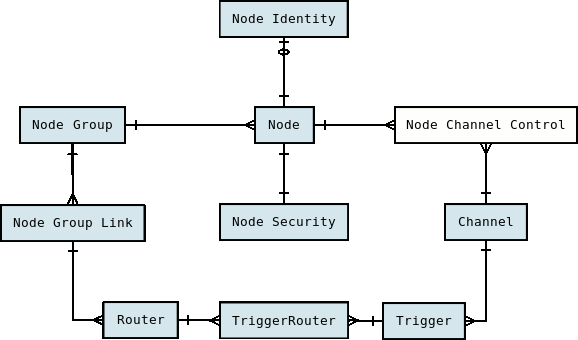
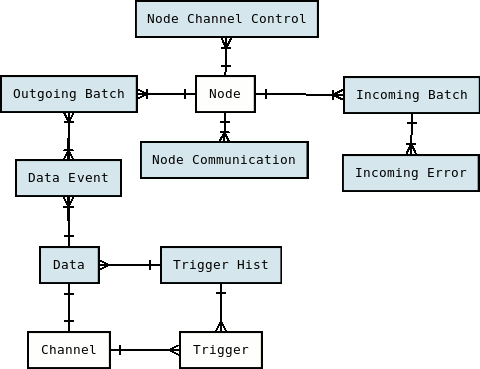
What follows is the complete SymmetricDS data model. Note that all tables are prepended with a configurable prefix so that multiple instances of SymmetricDS may coexist in the same database. The default prefix is sym_.
SymmetricDS configuration is entered by the user into the data model to control the behavior of what data is synchronized to which nodes.
At runtime, the configuration is used to capture data changes and route them to nodes. The data changes are placed together in a single unit called a batch that can be loaded by another node. Outgoing batches are delivered to nodes and acknowledged. Incoming batches are received and loaded. History is recorded for batch status changes and statistics.
This table represents a category of data that can be synchronized independently of other channels. Channels allow control over the type of data flowing and prevents one type of synchronization from contending with another.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| CHANNEL_ID | VARCHAR (128) | PK | X | A unique identifer, usually named something meaningful, like 'sales' or 'inventory'. | |
| PROCESSING_ORDER | INTEGER | 1 | X | Order of sequence to process channel data. | |
| MAX_BATCH_SIZE | INTEGER | 1000 | X | The maximum number of Data Events to process within a batch for this channel. | |
| MAX_BATCH_TO_SEND | INTEGER | 60 | X | The maximum number of batches to send during a 'synchronization' between two nodes. A 'synchronization' is equivalent to a push or a pull. If there are 12 batches ready to be sent for a channel and max_batch_to_send is equal to 10, then only the first 10 batches will be sent. | |
| MAX_DATA_TO_ROUTE | INTEGER | 100000 | X | The maximum number of data rows to route for a channel at a time. | |
| EXTRACT_PERIOD_MILLIS | INTEGER | 0 | X | The minimum number of milliseconds allowed between attempts to extract data for targeted at a node_id. | |
| ENABLED | INTEGER (1) | 1 | X | Indicates whether channel is enabled or not. | |
| USE_OLD_DATA_TO_ROUTE | INTEGER (1) | 1 | X | Indicates whether to read the old data during routing. | |
| USE_ROW_DATA_TO_ROUTE | INTEGER (1) | 1 | X | Indicates whether to read the row data during routing. | |
| USE_PK_DATA_TO_ROUTE | INTEGER (1) | 1 | X | Indicates whether to read the pk data during routing. | |
| RELOAD_FLAG | INTEGER (1) | 0 | X | Indicates that this channel is used for reloads. | |
| FILE_SYNC_FLAG | INTEGER (1) | 0 | X | Indicates that this channel is used for file sync. | |
| CONTAINS_BIG_LOB | INTEGER (1) | 0 | X | Provides SymmetricDS a hint on how to treat captured data. Currently only supported by Oracle. If set to '0', then selects for routing and data extraction will be more efficient and lobs will be truncated at 4k in the trigger text. When it is set to '0' there is a 4k limit on the total size of a row and on the size of a LOB column. Note, when switching this value back and forth triggers need to be forced to regenerate. | |
| BATCH_ALGORITHM | VARCHAR (50) | default | X | The algorithm to use when batching data on this channel. Possible values are: 'default', 'transactional', and 'nontransactional' | |
| DATA_LOADER_TYPE | VARCHAR (50) | default | X | Identify the type of data loader this channel should use. Allows for the default dataloader to be swapped out via configuration for more efficient platform specific data loaders. | |
| DESCRIPTION | VARCHAR (255) | Description on the type of data carried in this channel. | |||
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. | |||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | Timestamp when a user last updated this entry. |
Table A.1. CHANNEL
Defines how conflicts in row data should be handled during the load process.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| CONFLICT_ID | VARCHAR (50) | PK | X | Unique identifier for a specific conflict detection setting. | |
| source_node_group_id | VARCHAR (50) | FK | X | The source node group for which this setting will be applied to. References a node group link. | |
| target_node_group_id | VARCHAR (50) | FK | X | The target node group for which this setting will be applied to. References a node group link. | |
| TARGET_CHANNEL_ID | VARCHAR (128) | Optional channel that this setting will be applied to. | |||
| TARGET_CATALOG_NAME | VARCHAR (255) | Optional database catalog that the target table belongs to. Only use this if the target table is not in the default catalog. | |||
| TARGET_SCHEMA_NAME | VARCHAR (255) | Optional database schema that the target table belongs to. Only use this if the target table is not in the default schema. | |||
| TARGET_TABLE_NAME | VARCHAR (255) | Optional database table that this setting will apply to. If left blank, the setting will be for any table in the channel (if set) and in the specified node group link. | |||
| DETECT_TYPE | VARCHAR (128) | X | Indicates the strategy to use for detecting conflicts during a dml action. The possible values are: use_pk_data (manual, fallback, ignore), use_changed_data (manual, fallback, ignore), use_old_data (manual, fallback, ignore), use_timestamp (newer_wins), use_version (newer_wins) | ||
| DETECT_EXPRESSION | LONGVARCHAR | An expression that provides additional information about the detection mechanism. If the detection mechanism is use_timestamp or use_version then this expression will be the name of the timestamp or version column. | |||
| RESOLVE_TYPE | VARCHAR (128) | X | Indicates the strategy for resolving update conflicts. The possible values differ based on the detect_type that is specified. | ||
| PING_BACK | VARCHAR (128) | X | Indicates the strategy for sending resolved conflicts back to the source system. Possible values are: OFF, SINGLE_ROW, and REMAINING_ROWS. | ||
| RESOLVE_CHANGES_ONLY | INTEGER (1) | 0 | Indicates that when applying changes during an update that only data that has changed should be applied. Otherwise, all the columns will be updated. This really only applies to updates. | ||
| RESOLVE_ROW_ONLY | INTEGER (1) | 0 | Indicates that an action should take place for the entire batch if possible. This applies to a resolve type of 'ignore'. If a row is in conflict and the resolve type is 'ignore', then the entire batch will be ignored. | ||
| CREATE_TIME | TIMESTAMP | X | The date and time when this entry was created. | ||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | The date and time when a user last updated this entry. |
Table A.2. CONFLICT
The captured data change that occurred to a row in the database. Entries in data are created by database triggers.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| DATA_ID | BIGINT | PK | X | Unique identifier for a data. | |
| TABLE_NAME | VARCHAR (255) | X | The name of the table in which a change occurred that this entry records. | ||
| EVENT_TYPE | CHAR (1) | X | The type of event captured by this entry. For triggers, this is the change that occurred, which is 'I' for insert, 'U' for update, or 'D' for delete. Other events include: 'R' for reloading the entire table (or subset of the table) to the node; 'S' for running dynamic SQL at the node, which is used for adhoc administration. | ||
| ROW_DATA | LONGVARCHAR | The captured data change from the synchronized table. The column values are stored in comma-separated values (CSV) format. | |||
| PK_DATA | LONGVARCHAR | The primary key values of the captured data change from the synchronized table. This data is captured for updates and deletes. The primary key values are stored in comma-separated values (CSV) format. | |||
| OLD_DATA | LONGVARCHAR | The captured data values prior to the update. The column values are stored in CSV format. | |||
| TRIGGER_HIST_ID | INTEGER | X | The foreign key to the trigger_hist entry that contains the primary key and column names for the table being synchronized. | ||
| CHANNEL_ID | VARCHAR (128) | The channel that this data belongs to, such as 'prices' | |||
| TRANSACTION_ID | VARCHAR (255) | An optional transaction identifier that links multiple data changes together as the same transaction. | |||
| SOURCE_NODE_ID | VARCHAR (50) | If the data was inserted by a SymmetricDS data loader, then the id of the source node is record so that data is not re-routed back to it. | |||
| EXTERNAL_DATA | VARCHAR (50) | A field that can be populated by a trigger that uses the EXTERNAL_SELECT | |||
| NODE_LIST | VARCHAR (255) | A field that can be populated with a comma separated subset of node ids which will be the only nodes available to the router | |||
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. |
Table A.3. DATA
Each row represents the mapping between a data change that was captured and the batch that contains it. Entries in data_event are created as part of the routing process.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| DATA_ID | BIGINT | PK | X | Id of the data to be routed. | |
| BATCH_ID | BIGINT | PK | X | Id of the batch containing the data. | |
| ROUTER_ID | VARCHAR (50) | PK | X | Id of the router that routed this data_event. | |
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. |
Table A.4. DATA_EVENT
Used only when routing.data.reader.type is set to 'gap.' Table that tracks gaps in the data table so that they may be processed efficiently, if data shows up. Gaps can show up in the data table if a database transaction is rolled back.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| START_ID | BIGINT | PK | X | The first missing data_id from the data table where a gap is detected. This could be the last data_id inserted plus one. | |
| END_ID | BIGINT | PK | X | The last missing data_id from the data table where a gap is detected. If the start_id is the last data_id inserted plus one, then this field is filled in with a -1. | |
| STATUS | CHAR (2) | GP, SK, or FL. GP means there is a detected gap. FL means that the gap has been filled. SK means that the gap has been skipped either because the gap expired or because no database transaction was detected which means that no data will be committed to fill in the gap. | |||
| CREATE_TIME | TIMESTAMP | X | Timestamp when this entry was created. | ||
| LAST_UPDATE_HOSTNAME | VARCHAR (255) | The host who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. |
Table A.5. DATA_GAP
This table is used internally to request the extract of initial loads asynchronously when the initial load extract job is enabled.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| REQUEST_ID | BIGINT | PK | X | Unique identifier for a request. | |
| NODE_ID | VARCHAR (50) | X | The node_id of the batch being loaded. | ||
| STATUS | CHAR (2) | NE, OK | |||
| START_BATCH_ID | BIGINT | X | A load can be split across multiple batches. This is the first of N batches the load will be split across. | ||
| END_BATCH_ID | BIGINT | X | This is the last of N batches the load will be split across. | ||
| TRIGGER_ID | VARCHAR (128) | X | Unique identifier for a trigger associated with the extract request. | ||
| ROUTER_ID | VARCHAR (50) | X | Unique description of the router associated with the extract request. | ||
| LAST_UPDATE_TIME | TIMESTAMP | Timestamp when a process last updated this entry. | |||
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. |
Table A.6. EXTRACT_REQUEST
As files are loaded from another node the file and source node are captured here for file sync to use to prevent file ping backs in bidirectional file synchronization.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| RELATIVE_DIR | VARCHAR (255) | PK | X | The path to the file starting at the base_dir and excluding the file name itself. | |
| FILE_NAME | VARCHAR (128) | PK | X | The name of the file that has been loaded. | |
| LAST_EVENT_TYPE | CHAR (1) | X | The type of event that caused the file to be loaded from another node. 'C' is for create, 'M' is for modified, and 'D' is for deleted. | ||
| NODE_ID | VARCHAR (50) | X | The node_id of the source of the batch being loaded. | ||
| FILE_MODIFIED_TIME | BIGINT | The last modified time of the file at the time the file was loaded. |
Table A.7. FILE_INCOMING
Table used to capture file changes. Updates to the table are captured and routed according to the configured file trigger routers.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| TRIGGER_ID | VARCHAR (128) | PK | X | The id of the trigger that caused this snapshot to be taken. | |
| ROUTER_ID | VARCHAR (50) | PK | X | The id of the router that caused this snapshot to be taken. | |
| RELATIVE_DIR | VARCHAR (255) | PK | X | The path to the file starting at the base_dir | |
| FILE_NAME | VARCHAR (128) | PK | X | The name of the file that changed. | |
| CHANNEL_ID | VARCHAR (128) | filesync | X | The channel_id of the channel that data changes will flow through. | |
| RELOAD_CHANNEL_ID | VARCHAR (128) | filesync_reload | X | The channel_id of the channel that data changes will flow through. | |
| LAST_EVENT_TYPE | CHAR (1) | X | The type of event captured by this entry. 'C' is for create, 'M' is for modified, and 'D' is for deleted. | ||
| CRC32_CHECKSUM | BIGINT | File checksum. Can be used to determine if file content has changed. | |||
| FILE_SIZE | BIGINT | The size in bytes of the file at the time this change was detected. | |||
| FILE_MODIFIED_TIME | BIGINT | The last modified time of the file at the time this change was detected. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. | ||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| CREATE_TIME | TIMESTAMP | X | Timestamp when this entry was created. |
Table A.8. FILE_SNAPSHOT
This table defines files or sets of files for which changes will be captured for file synchronization
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| TRIGGER_ID | VARCHAR (128) | PK | X | Unique identifier for a trigger. | |
| CHANNEL_ID | VARCHAR (128) | filesync | X | The channel_id of the channel that data changes will flow through. | |
| RELOAD_CHANNEL_ID | VARCHAR (128) | filesync_reload | X | The channel_id of the channel that will be used for reloads. | |
| BASE_DIR | VARCHAR (255) | X | The base directory on the client that will be synchronized. | ||
| RECURSE | INTEGER (1) | 1 | X | Whether to synchronize child directories. | |
| INCLUDES_FILES | VARCHAR (255) | Wildcard-enabled, comma-separated list of file to include in synchronization. | |||
| EXCLUDES_FILES | VARCHAR (255) | Wildcard-enabled, comma-separated list of file to exclude from synchronization. | |||
| SYNC_ON_CREATE | INTEGER (1) | 1 | X | Whether to capture and send files when they are created. | |
| SYNC_ON_MODIFIED | INTEGER (1) | 1 | X | Whether to capture and send files when they are modified. | |
| SYNC_ON_DELETE | INTEGER (1) | 1 | X | Whether to capture and remove files when they are deleted. | |
| SYNC_ON_CTL_FILE | INTEGER (1) | 0 | X | Combined with sync_on_create, determines whether to capture and send files when a matching control file exists. The control file is a file of the same name with a '.ctl' extension appended to the end. | |
| DELETE_AFTER_SYNC | INTEGER (1) | 0 | X | Determines whether to delete the file after it has synced successfully. | |
| BEFORE_COPY_SCRIPT | LONGVARCHAR | A bsh script that is run right before the file copy. | |||
| AFTER_COPY_SCRIPT | LONGVARCHAR | A bsh script that is run right after the file copy. | |||
| CREATE_TIME | TIMESTAMP | X | Timestamp of when this entry was created. | ||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp of when a user last updated this entry. |
Table A.9. FILE_TRIGGER
Maps a file trigger to a router.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| trigger_id | VARCHAR (128) | PK FK | X | The id of a file trigger. | |
| router_id | VARCHAR (50) | PK FK | X | The id of a router. | |
| ENABLED | INTEGER (1) | 1 | X | Indicates whether this file trigger router is enabled or not. | |
| INITIAL_LOAD_ENABLED | INTEGER (1) | 1 | X | Indicates whether this file trigger should be initial loaded. | |
| TARGET_BASE_DIR | VARCHAR (255) | The base directory on the destination that files will be synchronized to. | |||
| CONFLICT_STRATEGY | VARCHAR (128) | source_wins | X | The strategy to employ when a file has been modified at both the client and the server. Possible values are: source_wins, target_wins, manual | |
| CREATE_TIME | TIMESTAMP | X | Timestamp when this entry was created. | ||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. |
Table A.10. FILE_TRIGGER_ROUTER
This tables defines named groups to which nodes can belong to based on their external id. Grouplets are used to designate that synchronization should only affect an explicit subset of nodes in a node group.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| GROUPLET_ID | VARCHAR (50) | PK | X | Unique identifier for the grouplet. | |
| GROUPLET_LINK_POLICY | CHAR (1) | I | X | Specified whether the external ids in the grouplet_link are included in the group or excluded from the grouplet. In the case of excluded, the grouplet starts with all external ids and removes the excluded ones listed. Use 'I' for inclusive and 'E' for exclusive. | |
| DESCRIPTION | VARCHAR (255) | A description of this grouplet. | |||
| CREATE_TIME | TIMESTAMP | X | Timestamp when this entry was created. | ||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. |
Table A.11. GROUPLET
This tables defines nodes belong to a grouplet based on their external.id
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| grouplet_id | VARCHAR (50) | PK FK | X | Unique identifier for the grouplet. | |
| EXTERNAL_ID | VARCHAR (50) | PK | X | Provides a means to select the nodes that belong to a grouplet. | |
| CREATE_TIME | TIMESTAMP | X | Timestamp when this entry was created. | ||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. |
Table A.12. GROUPLET_LINK
The incoming_batch is used for tracking the status of loading an outgoing_batch from another node. Data is loaded and commited at the batch level. The status of the incoming_batch is either successful (OK) or error (ER).
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| BATCH_ID | BIGINT (50) | PK | X | The id of the outgoing_batch that is being loaded. | |
| NODE_ID | VARCHAR (50) | PK | X | The node_id of the source of the batch being loaded. | |
| CHANNEL_ID | VARCHAR (128) | The channel_id of the batch being loaded. | |||
| STATUS | CHAR (2) | The current status of the batch can be loading (LD), successfully loaded (OK), in error (ER) or skipped (SK) | |||
| ERROR_FLAG | INTEGER (1) | 0 | A flag that indicates that this batch was in error during the last synchornization attempt. | ||
| NETWORK_MILLIS | BIGINT | 0 | X | The number of milliseconds spent transfering this batch across the network. | |
| FILTER_MILLIS | BIGINT | 0 | X | The number of milliseconds spent in filters processing data. | |
| DATABASE_MILLIS | BIGINT | 0 | X | The number of milliseconds spent loading the data into the target database. | |
| FAILED_ROW_NUMBER | BIGINT | 0 | X | This numbered data event that failed as read from the CSV. | |
| FAILED_LINE_NUMBER | BIGINT | 0 | X | The current line number in the CSV for this batch that failed. | |
| BYTE_COUNT | BIGINT | 0 | X | The number of bytes that were sent as part of this batch. | |
| STATEMENT_COUNT | BIGINT | 0 | X | The number of statements run to load this batch. | |
| FALLBACK_INSERT_COUNT | BIGINT | 0 | X | The number of times an update was turned into an insert because the data was not already in the target database. | |
| FALLBACK_UPDATE_COUNT | BIGINT | 0 | X | The number of times an insert was turned into an update because a data row already existed in the target database. | |
| IGNORE_COUNT | BIGINT | 0 | X | The number of times a row was ignored. | |
| MISSING_DELETE_COUNT | BIGINT | 0 | X | The number of times a delete did not affect the database because the row was already deleted. | |
| SKIP_COUNT | BIGINT | 0 | X | The number of times a batch was sent and skipped because it had already been loaded according to incoming_batch. | |
| SQL_STATE | VARCHAR (10) | For a status of error (ER), this is the XOPEN or SQL 99 SQL State. | |||
| SQL_CODE | INTEGER | 0 | X | For a status of error (ER), this is the error code from the database that is specific to the vendor. | |
| SQL_MESSAGE | LONGVARCHAR | For a status of error (ER), this is the error message that describes the error. | |||
| LAST_UPDATE_HOSTNAME | VARCHAR (255) | The host name of the process that last did work on this batch. | |||
| LAST_UPDATE_TIME | TIMESTAMP | Timestamp when a process last updated this entry. | |||
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. |
Table A.13. INCOMING_BATCH
The captured data change that is in error for a batch. The user can tell the system what to do by updating the resolve columns. Entries in data_error are created when an incoming batch encounters an error.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| BATCH_ID | BIGINT (50) | PK | X | The id of the outgoing_batch that is being loaded. | |
| NODE_ID | VARCHAR (50) | PK | X | The node_id of the source of the batch being loaded. | |
| FAILED_ROW_NUMBER | BIGINT | PK | X | The row number in the batch that encountered an error when loading. | |
| FAILED_LINE_NUMBER | BIGINT | 0 | X | The current line number in the CSV for this batch that failed. | |
| TARGET_CATALOG_NAME | VARCHAR (255) | The catalog name for the table being loaded. | |||
| TARGET_SCHEMA_NAME | VARCHAR (255) | The schema name for the table being loaded. | |||
| TARGET_TABLE_NAME | VARCHAR (255) | X | The table name for the table being loaded. | ||
| EVENT_TYPE | CHAR (1) | X | The type of event captured by this entry. For triggers, this is the change that occurred, which is 'I' for insert, 'U' for update, or 'D' for delete. Other events include: 'R' for reloading the entire table (or subset of the table) to the node; 'S' for running dynamic SQL at the node, which is used for adhoc administration. | ||
| BINARY_ENCODING | VARCHAR (10) | HEX | X | The type of encoding the source system used for encoding binary data. | |
| COLUMN_NAMES | LONGVARCHAR | X | The column names defined on the table. The column names are stored in comma-separated values (CSV) format. | ||
| PK_COLUMN_NAMES | LONGVARCHAR | X | The primary key column names defined on the table. The column names are stored in comma-separated values (CSV) format. | ||
| ROW_DATA | LONGVARCHAR | The row data from the batch as captured from the source. The column values are stored in comma-separated values (CSV) format. | |||
| OLD_DATA | LONGVARCHAR | The old row data prior to update from the batch as captured from the source. The column values are stored in CSV format. | |||
| CUR_DATA | LONGVARCHAR | The current row data that caused the error to occur. The column values are stored in CSV format. | |||
| RESOLVE_DATA | LONGVARCHAR | The capture data change from the user that is used instead of row_data. This is useful when resolving a conflict manually by specifying the data that should load. | |||
| RESOLVE_IGNORE | INTEGER (1) | 0 | Indication from the user that the row_data should be ignored and the batch can continue loading with the next row. | ||
| CONFLICT_ID | VARCHAR (50) | Unique identifier for the conflict detection setting that caused the error | |||
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. | |||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. |
Table A.14. INCOMING_ERROR
A table that allows you to dynamically define filters using bsh.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| LOAD_FILTER_ID | VARCHAR (50) | PK | X | The id of the load filter. | |
| LOAD_FILTER_TYPE | VARCHAR (10) | X | The type of load filter. Currently 'bsh'. May add 'sql' in the future. | ||
| SOURCE_NODE_GROUP_ID | VARCHAR (50) | X | The source node group for the filter. | ||
| TARGET_NODE_GROUP_ID | VARCHAR (50) | X | The destination node group for the filter. | ||
| TARGET_CATALOG_NAME | VARCHAR (255) | Optional name for the catalog the configured table is in. | |||
| TARGET_SCHEMA_NAME | VARCHAR (255) | Optional name for the schema a configured table is in. | |||
| TARGET_TABLE_NAME | VARCHAR (255) | The name of the target table that will trigger the bsh filter. | |||
| FILTER_ON_UPDATE | INTEGER (1) | 1 | X | Whether or not the filter should apply on an update. | |
| FILTER_ON_INSERT | INTEGER (1) | 1 | X | Whether or not the filter should apply on an insert. | |
| FILTER_ON_DELETE | INTEGER (1) | 1 | X | Whether or not the filter should apply on a delete. | |
| BEFORE_WRITE_SCRIPT | LONGVARCHAR | The script to apply before the write is completed. | |||
| AFTER_WRITE_SCRIPT | LONGVARCHAR | The script to apply after the write is completed. | |||
| BATCH_COMPLETE_SCRIPT | LONGVARCHAR | The script to apply on batch complete. | |||
| BATCH_COMMIT_SCRIPT | LONGVARCHAR | The script to apply on batch commit. | |||
| BATCH_ROLLBACK_SCRIPT | LONGVARCHAR | The script to apply on batch rollback. | |||
| HANDLE_ERROR_SCRIPT | LONGVARCHAR | The script to apply when data cannot be processed. | |||
| CREATE_TIME | TIMESTAMP | X | Timestamp when this entry was created. | ||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. | ||
| LOAD_FILTER_ORDER | INTEGER | 1 | X | Specifies the order in which to apply load filters if more than one target operation occurs. | |
| FAIL_ON_ERROR | INTEGER (1) | 0 | X | Whether we should fail the batch if the filter fails. |
Table A.15. LOAD_FILTER
Contains semaphores that are set when processes run, so that only one server can run a process at a time. Enable this feature by using the cluster.lock.during.xxxx parameters.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| LOCK_ACTION | VARCHAR (50) | PK | X | The process that needs a lock. | |
| LOCK_TYPE | VARCHAR (50) | X | Type of lock that indicates differently locking behavior. Types include cluster, exclusive, and shared. Cluster lock is used to allow one server to run at a time, but any process from the same server can overtake the lock, which avoids stalled processing. Exclusive lock is owned by one process, regardless of which server it is on, but another process can acquire the lock after lock_time is older than exclusive.lock.timeout.ms. Shared lock allows multiple processes to use the same lock, incrementing the shared_count, but requires no exclusive lock exists and prevents an exclusive lock. | ||
| LOCKING_SERVER_ID | VARCHAR (255) | The name of the server that currently has a lock. This is typically a host name, but it can be overridden using the -Druntime.symmetric.cluster.server.id=name System property. | |||
| LOCK_TIME | TIMESTAMP | The time a lock is aquired. Use the cluster.lock.timeout.ms to specify a lock timeout period. | |||
| SHARED_COUNT | INTEGER | 0 | X | For a lock_type of SHARED, this is the number of processes sharing the same lock. After the shared_count drops to zero, a shared lock is removed. | |
| SHARED_ENABLE | INTEGER | 0 | X | For a lock_type of SHARED, this flag set to 1 indicates that more processes can share the lock. If an exclusive lock is needed, the flag is set to 0 to prevent further shared locks from accumulating. | |
| LAST_LOCK_TIME | TIMESTAMP | Timestamp when a process last updated this entry. | |||
| LAST_LOCKING_SERVER_ID | VARCHAR (255) | The server id of the process that last did work on this batch. |
Table A.16. LOCK
Representation of an instance of SymmetricDS that synchronizes data with one or more additional nodes. Each node has a unique identifier (nodeId) that is used when communicating, as well as a domain-specific identifier (externalId) that provides context within the local system.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| NODE_ID | VARCHAR (50) | PK | X | A unique identifier for a node. | |
| NODE_GROUP_ID | VARCHAR (50) | X | The node group that this node belongs to, such as 'store'. | ||
| EXTERNAL_ID | VARCHAR (50) | X | A domain-specific identifier for context within the local system. For example, the retail store number. | ||
| SYNC_ENABLED | INTEGER (1) | 0 | Indicates whether this node should be sent synchronization. Disabled nodes are ignored by the triggers, so no entries are made in data_event for the node. | ||
| SYNC_URL | VARCHAR (255) | The URL to contact the node for synchronization. | |||
| SCHEMA_VERSION | VARCHAR (50) | The version of the database schema this node manages. Useful for specifying synchronization by version. | |||
| SYMMETRIC_VERSION | VARCHAR (50) | The version of SymmetricDS running at this node. | |||
| DATABASE_TYPE | VARCHAR (50) | The database product name at this node as reported by JDBC. | |||
| DATABASE_VERSION | VARCHAR (50) | The database product version at this node as reported by JDBC. | |||
| HEARTBEAT_TIME | TIMESTAMP | Deprecated. Use node_host.heartbeat_time instead. | |||
| TIMEZONE_OFFSET | VARCHAR (6) | Deprecated. Use node_host.timezone_offset instead. | |||
| BATCH_TO_SEND_COUNT | INTEGER | 0 | The number of outgoing batches that have not yet been sent. This field is updated as part of the heartbeat job if the heartbeat.update.node.with.batch.status property is set to true. | ||
| BATCH_IN_ERROR_COUNT | INTEGER | 0 | The number of outgoing batches that are in error at this node. This field is updated as part of the heartbeat job if the heartbeat.update.node.with.batch.status property is set to true. | ||
| CREATED_AT_NODE_ID | VARCHAR (50) | The node_id of the node where this node was created. This is typically filled automatically with the node_id found in node_identity where registration was opened for the node. | |||
| DEPLOYMENT_TYPE | VARCHAR (50) | An indicator as to the type of SymmetricDS software that is running. Possible values are, but not limited to: engine, standalone, war, professional, mobile |
Table A.17. NODE
This table is used to coordinate communication with other nodes.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| NODE_ID | VARCHAR (50) | PK | X | Unique identifier for a node. | |
| COMMUNICATION_TYPE | VARCHAR (10) | PK | X | The type of communication that is taking place with this node. Valid values are: PULL, PUSH | |
| LOCK_TIME | TIMESTAMP | The timestamp when this node was locked | |||
| LOCKING_SERVER_ID | VARCHAR (255) | The name of the server that currently has a pull lock for the node. This is typically a host name, but it can be overridden using the -Druntime.symmetric.cluster.server.id=name System property. | |||
| LAST_LOCK_TIME | TIMESTAMP | The timestamp when this node was last locked | |||
| LAST_LOCK_MILLIS | BIGINT | 0 | The amount of time the last communication took. | ||
| SUCCESS_COUNT | BIGINT | 0 | The number of successive successful communication attempts. | ||
| FAIL_COUNT | BIGINT | 0 | The number of successive failed communication attempts. | ||
| TOTAL_SUCCESS_COUNT | BIGINT | 0 | The total number of successful communication attempts with the node. | ||
| TOTAL_FAIL_COUNT | BIGINT | 0 | The total number of failed communication attempts with the node. | ||
| TOTAL_SUCCESS_MILLIS | BIGINT | 0 | The total amount of time spent during successful communication attempts with the node. | ||
| TOTAL_FAIL_MILLIS | BIGINT | 0 | The total amount of time spent during failed communication attempts with the node. |
Table A.18. NODE_COMMUNICATION
Used to ignore or suspend a channel. A channel that is ignored will have its data_events batched and they will immediately be marked as 'OK' without sending them. A channel that is suspended is skipped when batching data_events.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| NODE_ID | VARCHAR (50) | PK | X | Unique identifier for a node. | |
| CHANNEL_ID | VARCHAR (128) | PK | X | The name of the channel_id that is being controlled. | |
| SUSPEND_ENABLED | INTEGER (1) | 0 | Indicates if this channel is suspended, which prevents its Data Events from being batched. | ||
| IGNORE_ENABLED | INTEGER (1) | 0 | Indicates if this channel is ignored, which marks its Data Events as if they were actually processed. | ||
| LAST_EXTRACT_TIME | TIMESTAMP | Record the last time data was extract for a node and a channel. |
Table A.19. NODE_CHANNEL_CTL
A category of Nodes that synchronizes data with one or more NodeGroups. A common use of NodeGroup is to describe a level in a hierarchy of data synchronization.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| NODE_GROUP_ID | VARCHAR (50) | PK | X | Unique identifier for a node group, usually named something meaningful, like 'store' or 'warehouse'. | |
| DESCRIPTION | VARCHAR (255) | A description of this node group. | |||
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. | |||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | Timestamp when a user last updated this entry. |
Table A.20. NODE_GROUP
An optional window of time for which a node group and channel will extract and send data.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| NODE_GROUP_ID | VARCHAR (50) | PK | X | The node_group_id that this window applies to. | |
| CHANNEL_ID | VARCHAR (128) | PK | X | The channel_id that this window applies to. | |
| START_TIME | TIME | PK | X | The start time for the active window. | |
| END_TIME | TIME | PK | X | The end time for the active window. Note that if the end_time is less than the start_time then the window crosses a day boundary. | |
| ENABLED | INTEGER (1) | 0 | X | Enable this window. If this is set to '0' then this window is ignored. |
Table A.21. NODE_GROUP_CHANNEL_WND
A source node_group sends its data updates to a target NodeGroup using a pull, push, or custom technique.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| source_node_group_id | VARCHAR (50) | PK FK | X | The node group where data changes should be captured. | |
| target_node_group_id | VARCHAR (50) | PK FK | X | The node group where data changes will be sent. | |
| DATA_EVENT_ACTION | CHAR (1) | W | X | The notification scheme used to send data changes to the target node group. (P = Push, W = Wait for Pull, R = Route-Only) | |
| SYNC_CONFIG_ENABLED | INTEGER (1) | 1 | Indicates whether configuration that has changed should be synchronized to target nodes on this link. | ||
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. | |||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | Timestamp when a user last updated this entry. |
Table A.22. NODE_GROUP_LINK
Representation of an physical workstation or server that is hosting the SymmetricDS software. In a clustered environment there may be more than one entry per node in this table.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| node_id | VARCHAR (50) | PK FK | X | A unique identifier for a node. | |
| HOST_NAME | VARCHAR (60) | PK | X | The host name of a workstation or server. If more than one instance of SymmetricDS runs on the same server, then this value can be a 'server id' specified by -Druntime.symmetric.cluster.server.id | |
| IP_ADDRESS | VARCHAR (50) | The ip address for the host. | |||
| OS_USER | VARCHAR (50) | The user SymmetricDS is running under | |||
| OS_NAME | VARCHAR (50) | The name of the OS | |||
| OS_ARCH | VARCHAR (50) | The hardware architecture of the OS | |||
| OS_VERSION | VARCHAR (50) | The version of the OS | |||
| AVAILABLE_PROCESSORS | INTEGER | 0 | The number of processors available to use. | ||
| FREE_MEMORY_BYTES | BIGINT | 0 | The amount of free memory available to the JVM. | ||
| TOTAL_MEMORY_BYTES | BIGINT | 0 | The amount of total memory available to the JVM. | ||
| MAX_MEMORY_BYTES | BIGINT | 0 | The max amount of memory available to the JVM. | ||
| JAVA_VERSION | VARCHAR (50) | The version of java that SymmetricDS is running as. | |||
| JAVA_VENDOR | VARCHAR (255) | The vendor of java that SymmetricDS is running as. | |||
| JDBC_VERSION | VARCHAR (255) | The verision of the JDBC driver that is being used. | |||
| SYMMETRIC_VERSION | VARCHAR (50) | The version of SymmetricDS running at this node. | |||
| TIMEZONE_OFFSET | VARCHAR (6) | The time zone offset in RFC822 format at the time of the last heartbeat. | |||
| HEARTBEAT_TIME | TIMESTAMP | The last timestamp when the node sent a heartbeat, which is attempted every ten minutes by default. | |||
| LAST_RESTART_TIME | TIMESTAMP | X | Timestamp when this instance was last restarted. | ||
| CREATE_TIME | TIMESTAMP | X | Timestamp when this entry was created. |
Table A.23. NODE_HOST
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| NODE_ID | VARCHAR (50) | PK | X | A unique identifier for a node. | |
| HOST_NAME | VARCHAR (60) | PK | X | The host name of a workstation or server. If more than one instance of SymmetricDS runs on the same server, then this value can be a 'server id' specified by -Druntime.symmetric.cluster.server.id | |
| CHANNEL_ID | VARCHAR (128) | PK | X | The channel_id of the channel that data changes will flow through. | |
| START_TIME | TIMESTAMP | PK | X | The start time for the period which this row represents. | |
| END_TIME | TIMESTAMP | PK | X | The end time for the period which this row represents. | |
| DATA_ROUTED | BIGINT | 0 | Indicate the number of data rows that have been routed during this period. | ||
| DATA_UNROUTED | BIGINT | 0 | The amount of data that has not yet been routed at the time this stats row was recorded. | ||
| DATA_EVENT_INSERTED | BIGINT | 0 | Indicate the number of data rows that have been routed during this period. | ||
| DATA_EXTRACTED | BIGINT | 0 | The number of data rows that were extracted during this time period. | ||
| DATA_BYTES_EXTRACTED | BIGINT | 0 | The number of bytes that were extracted during this time period. | ||
| DATA_EXTRACTED_ERRORS | BIGINT | 0 | The number of errors that occurred during extraction during this time period. | ||
| DATA_BYTES_SENT | BIGINT | 0 | The number of bytes that were sent during this time period. | ||
| DATA_SENT | BIGINT | 0 | The number of rows that were sent during this time period. | ||
| DATA_SENT_ERRORS | BIGINT | 0 | The number of errors that occurred while sending during this time period. | ||
| DATA_LOADED | BIGINT | 0 | The number of rows that were loaded during this time period. | ||
| DATA_BYTES_LOADED | BIGINT | 0 | The number of bytes that were loaded during this time period. | ||
| DATA_LOADED_ERRORS | BIGINT | 0 | The number of errors that occurred while loading during this time period. |
Table A.24. NODE_HOST_CHANNEL_STATS
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| NODE_ID | VARCHAR (50) | PK | X | A unique identifier for a node. | |
| HOST_NAME | VARCHAR (60) | PK | X | The host name of a workstation or server. If more than one instance of SymmetricDS runs on the same server, then this value can be a 'server id' specified by -Druntime.symmetric.cluster.server.id | |
| JOB_NAME | VARCHAR (50) | PK | X | The name of the job. | |
| START_TIME | TIMESTAMP | PK | X | The start time for the period which this row represents. | |
| END_TIME | TIMESTAMP | PK | X | The end time for the period which this row represents. | |
| PROCESSED_COUNT | BIGINT | 0 | The number of items that were processed during the job run. |
Table A.25. NODE_HOST_JOB_STATS
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| NODE_ID | VARCHAR (50) | PK | X | A unique identifier for a node. | |
| HOST_NAME | VARCHAR (60) | PK | X | The host name of a workstation or server. If more than one instance of SymmetricDS runs on the same server, then this value can be a 'server id' specified by -Druntime.symmetric.cluster.server.id | |
| START_TIME | TIMESTAMP | PK | X | The end time for the period which this row represents. | |
| END_TIME | TIMESTAMP | PK | X | ||
| RESTARTED | BIGINT | 0 | X | Indicate that a restart occurred during this period. | |
| NODES_PULLED | BIGINT | 0 | |||
| TOTAL_NODES_PULL_TIME | BIGINT | 0 | |||
| NODES_PUSHED | BIGINT | 0 | |||
| TOTAL_NODES_PUSH_TIME | BIGINT | 0 | |||
| NODES_REJECTED | BIGINT | 0 | |||
| NODES_REGISTERED | BIGINT | 0 | |||
| NODES_LOADED | BIGINT | 0 | |||
| NODES_DISABLED | BIGINT | 0 | |||
| PURGED_DATA_ROWS | BIGINT | 0 | |||
| PURGED_DATA_EVENT_ROWS | BIGINT | 0 | |||
| PURGED_BATCH_OUTGOING_ROWS | BIGINT | 0 | |||
| PURGED_BATCH_INCOMING_ROWS | BIGINT | 0 | |||
| TRIGGERS_CREATED_COUNT | BIGINT | ||||
| TRIGGERS_REBUILT_COUNT | BIGINT | ||||
| TRIGGERS_REMOVED_COUNT | BIGINT |
Table A.26. NODE_HOST_STATS
After registration, this table will have one row representing the identity of the node. For a root node, the row is entered by the user.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| node_id | VARCHAR (50) | PK FK | X | Unique identifier for a node. |
Table A.27. NODE_IDENTITY
Security features like node passwords and open registration flag are stored in the node_security table.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| node_id | VARCHAR (50) | PK FK | X | Unique identifier for a node. | |
| NODE_PASSWORD | VARCHAR (50) | X | The password used by the node to prove its identity during synchronization. | ||
| REGISTRATION_ENABLED | INTEGER (1) | 0 | Indicates whether registration is open for this node. Re-registration may be forced for a node if this is set back to '1' in a parent database for the node_id that should be re-registred. | ||
| REGISTRATION_TIME | TIMESTAMP | The timestamp when this node was last registered. | |||
| INITIAL_LOAD_ENABLED | INTEGER (1) | 0 | Indicates whether an initial load will be sent to this node. | ||
| INITIAL_LOAD_TIME | TIMESTAMP | The timestamp when an initial load was started for this node. | |||
| INITIAL_LOAD_ID | BIGINT | A reference to the load_id in outgoing_batch for the last load that occurred. | |||
| INITIAL_LOAD_CREATE_BY | VARCHAR (255) | The user that created the initial load. A null value means that the system created the batch. | |||
| REV_INITIAL_LOAD_ENABLED | INTEGER (1) | 0 | Indicates that this node should send a reverse initial load. | ||
| REV_INITIAL_LOAD_TIME | TIMESTAMP | The timestamp when this node last sent an initial load. | |||
| REV_INITIAL_LOAD_ID | BIGINT | A reference to the load_id in outgoing_batch for the last reverse load that occurred. | |||
| REV_INITIAL_LOAD_CREATE_BY | VARCHAR (255) | The user that created the reverse initial load. A null value means that the system created the batch. | |||
| CREATED_AT_NODE_ID | VARCHAR (50) | X | The node_id of the node where this node was created. This is typically filled automatically with the node_id found in node_identity where registration was opened for the node. |
Table A.28. NODE_SECURITY
Used for tracking the sending a collection of data to a node in the system. A new outgoing_batch is created and given a status of 'NE'. After sending the outgoing_batch to its target node, the status becomes 'SE'. The node responds with either a success status of 'OK' or an error status of 'ER'. An error while sending to the node also results in an error status of 'ER' regardless of whether the node sends that acknowledgement.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| BATCH_ID | BIGINT | PK | X | A unique id for the batch. | |
| NODE_ID | VARCHAR (50) | PK | X | The node that this batch is targeted at. | |
| CHANNEL_ID | VARCHAR (128) | The channel that this batch is part of. | |||
| STATUS | CHAR (2) | The current status of a batch can be routing (RT), newly created and ready for replication (NE), being queried from the database (QY), sent to a Node (SE), ready to be loaded (LD) and acknowledged as successful (OK), ignored (IG) or in error (ER). | |||
| LOAD_ID | BIGINT | An id that ties multiple batches together to identify them as being part of an initial load. | |||
| EXTRACT_JOB_FLAG | INTEGER (1) | 0 | A flag that indicates that this batch is going to be extracted by another job. | ||
| LOAD_FLAG | INTEGER (1) | 0 | A flag that indicates that this batch is part of an initial load. | ||
| ERROR_FLAG | INTEGER (1) | 0 | A flag that indicates that this batch was in error during the last synchornization attempt. | ||
| COMMON_FLAG | INTEGER (1) | 0 | A flag that indicates that the data in this batch is shared by other nodes (they will have the same batch_id). Shared batches will be extracted to a common location. | ||
| IGNORE_COUNT | BIGINT | 0 | X | The number of times a batch was ignored. | |
| BYTE_COUNT | BIGINT | 0 | X | The number of bytes that were sent as part of this batch. | |
| EXTRACT_COUNT | BIGINT | 0 | X | The number of times this an attempt to extract this batch occurred. | |
| SENT_COUNT | BIGINT | 0 | X | The number of times this batch was sent. A batch can be sent multiple times if an ACK is not received. | |
| LOAD_COUNT | BIGINT | 0 | X | The number of times an attempt to load this batch occurred. | |
| DATA_EVENT_COUNT | BIGINT | 0 | X | The number of data_events that are part of this batch. | |
| RELOAD_EVENT_COUNT | BIGINT | 0 | X | The number of reload events that are part of this batch. | |
| INSERT_EVENT_COUNT | BIGINT | 0 | X | The number of insert events that are part of this batch. | |
| UPDATE_EVENT_COUNT | BIGINT | 0 | X | The number of update events that are part of this batch. | |
| DELETE_EVENT_COUNT | BIGINT | 0 | X | The number of delete events that are part of this batch. | |
| OTHER_EVENT_COUNT | BIGINT | 0 | X | The number of other event types that are part of this batch. This includes any events types that are not a reload, insert, update or delete event type. | |
| ROUTER_MILLIS | BIGINT | 0 | X | The number of milliseconds spent creating this batch. | |
| NETWORK_MILLIS | BIGINT | 0 | X | The number of milliseconds spent transfering this batch across the network. | |
| FILTER_MILLIS | BIGINT | 0 | X | The number of milliseconds spent in filters processing data. | |
| LOAD_MILLIS | BIGINT | 0 | X | The number of milliseconds spent loading the data into the target database. | |
| EXTRACT_MILLIS | BIGINT | 0 | X | The number of milliseconds spent extracting the data out of the source database. | |
| SQL_STATE | VARCHAR (10) | For a status of error (ER), this is the XOPEN or SQL 99 SQL State. | |||
| SQL_CODE | INTEGER | 0 | X | For a status of error (ER), this is the error code from the database that is specific to the vendor. | |
| SQL_MESSAGE | LONGVARCHAR | For a status of error (ER), this is the error message that describes the error. | |||
| FAILED_DATA_ID | BIGINT | 0 | X | For a status of error (ER), this is the data_id that was being processed when the batch failed. | |
| FAILED_LINE_NUMBER | BIGINT | 0 | X | The current line number in the CSV for this batch that failed. | |
| LAST_UPDATE_HOSTNAME | VARCHAR (255) | The host name of the process that last did work on this batch. | |||
| LAST_UPDATE_TIME | TIMESTAMP | Timestamp when a process last updated this entry. | |||
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. | |||
| CREATE_BY | VARCHAR (255) | The user that created the batch. A null value means that the system created the batch. |
Table A.29. OUTGOING_BATCH
Provides a way to manage most SymmetricDS settings in the database.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| EXTERNAL_ID | VARCHAR (50) | PK | X | Target the parameter at a specific external id. To target all nodes, use the value of 'ALL.' | |
| NODE_GROUP_ID | VARCHAR (50) | PK | X | Target the parameter at a specific node group id. To target all groups, use the value of 'ALL.' | |
| PARAM_KEY | VARCHAR (80) | PK | X | The name of the parameter. | |
| PARAM_VALUE | LONGVARCHAR | The value of the parameter. | |||
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. | |||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | Timestamp when a user last updated this entry. |
Table A.30. PARAMETER
Provides a way for a centralized registration server to redirect registering nodes to their prospective parent node in a multi-tiered deployment.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| REGISTRANT_EXTERNAL_ID | VARCHAR (50) | PK | X | Maps the external id of a registration request to a different parent node. | |
| REGISTRATION_NODE_ID | VARCHAR (50) | X | The node_id of the node that a registration request should be redirected to. |
Table A.31. REGISTRATION_REDIRECT
Audits when a node registers or attempts to register.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| NODE_GROUP_ID | VARCHAR (50) | PK | X | The node group that this node belongs to, such as 'store'. | |
| EXTERNAL_ID | VARCHAR (50) | PK | X | A domain-specific identifier for context within the local system. For example, the retail store number. | |
| STATUS | CHAR (2) | X | The current status of the registration attempt. Valid statuses are NR (not registered), IG (ignored), OK (sucessful) | ||
| HOST_NAME | VARCHAR (60) | X | The host name of a workstation or server. If more than one instance of SymmetricDS runs on the same server, then this value can be a 'server id' specified by -Druntime.symmetric.cluster.server.id | ||
| IP_ADDRESS | VARCHAR (50) | X | The ip address for the host. | ||
| ATTEMPT_COUNT | INTEGER | 0 | The number of registration attempts. | ||
| REGISTERED_NODE_ID | VARCHAR (50) | A unique identifier for a node. | |||
| ERROR_MESSAGE | LONGVARCHAR | Record any errors or warnings that occurred when attempting to register. | |||
| CREATE_TIME | TIMESTAMP | PK | X | Timestamp when this entry was created. | |
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. |
Table A.32. REGISTRATION_REQUEST
Configure a type of router from one node group to another. Note that routers are mapped to triggers through trigger_routers.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| ROUTER_ID | VARCHAR (50) | PK | X | Unique description of a specific router | |
| TARGET_CATALOG_NAME | VARCHAR (255) | Optional name for the catalog a target table is in. Only use this if the target table is not in the default catalog. If this field is left blank, then the source_catalog_name for the trigger will be used as the target name. If the target name should be left blank and the source name is set, then the token of $(none) may be used to force the target name to be blanked out. | |||
| TARGET_SCHEMA_NAME | VARCHAR (255) | Optional name of the schema a target table is in. On use this if the target table is not in the default schema. If this field is left blank, then the source_schema_name for the trigger will be used as the target name. If the target name should be left blank and the source name is set, then the token of $(none) may be used to force the target name to be blanked out. | |||
| TARGET_TABLE_NAME | VARCHAR (255) | Optional name for a target table. Only use this if the target table name is different than the source. | |||
| source_node_group_id | VARCHAR (50) | FK | X | Routers with this node_group_id will install triggers that are mapped to this router. | |
| target_node_group_id | VARCHAR (50) | FK | X | The node_group_id for nodes to route data to. Note that routing can be further narrowed down by the configured router_type and router_expression. | |
| ROUTER_TYPE | VARCHAR (50) | The name of a specific type of router. Out of the box routers are 'default','column','bsh', 'subselect' and 'audit.' Custom routers can be configured as extension points. | |||
| ROUTER_EXPRESSION | LONGVARCHAR | An expression that is specific to the type of router that is configured in router_type. See the documentation for each router for more details. | |||
| SYNC_ON_UPDATE | INTEGER (1) | 1 | X | Flag that indicates that this router should route updates. | |
| SYNC_ON_INSERT | INTEGER (1) | 1 | X | Flag that indicates that this router should route inserts. | |
| SYNC_ON_DELETE | INTEGER (1) | 1 | X | Flag that indicates that this router should route deletes. | |
| USE_SOURCE_CATALOG_SCHEMA | INTEGER (1) | 1 | X | Whether or not to assume that the target catalog/schema name should be the same as the source catalog/schema name. The target catalog or schema name will still override if not blank. | |
| CREATE_TIME | TIMESTAMP | X | Timestamp when this entry was created. | ||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. |
Table A.33. ROUTER
A table that supports application level sequence numbering.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| SEQUENCE_NAME | VARCHAR (50) | PK | X | Unique identifier of a specific sequence. | |
| CURRENT_VALUE | BIGINT | 0 | X | The current value of the sequence. | |
| INCREMENT_BY | INTEGER | 1 | X | Specify the interval between sequence numbers. This integer value can be any positive or negative integer, but it cannot be 0. | |
| MIN_VALUE | BIGINT | 1 | X | Specify the minimum value of the sequence. | |
| MAX_VALUE | BIGINT | 9999999999 | X | Specify the maximum value the sequence can generate. | |
| CYCLE | INTEGER (1) | 0 | Indicate whether the sequence should automatically cycle once a boundary is hit. | ||
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. | |||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. |
Table A.34. SEQUENCE
This table acts as a means to queue up a reload of a specific table. Either the target or the source node may insert into this table to queue up a load. If the target node inserts into the table, then the row will be synchronized to the source node and the reload events will be queued up during routing.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| TARGET_NODE_ID | VARCHAR (50) | PK | X | Unique identifier for the node to receive the table reload. | |
| SOURCE_NODE_ID | VARCHAR (50) | PK | X | Unique identifier for the node that will be the source of the table reload. | |
| TRIGGER_ID | VARCHAR (128) | PK | X | Unique identifier for a trigger associated with the table reload. Note the trigger must be linked to the router. | |
| ROUTER_ID | VARCHAR (50) | PK | X | Unique description of the router associated with the table reload. Note the router must be linked to the trigger. | |
| RELOAD_SELECT | LONGVARCHAR | Overrides the initial load select. | |||
| RELOAD_DELETE_STMT | LONGVARCHAR | Overrides the initial load delete statement. | |||
| RELOAD_ENABLED | INTEGER (1) | 0 | Indicates that a reload should be queued up. | ||
| RELOAD_TIME | TIMESTAMP | The timestamp when the reload was started for this node. | |||
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. | |||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. |
Table A.35. TABLE_RELOAD_REQUEST
Defines a data loader transformation which can be used to map arbitrary tables and columns to other tables and columns.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| TRANSFORM_ID | VARCHAR (50) | PK | X | Unique identifier of a specific transform. | |
| source_node_group_id | VARCHAR (50) | PK FK | X | The node group where data changes are captured. | |
| target_node_group_id | VARCHAR (50) | PK FK | X | The node group where data changes will be sent. | |
| TRANSFORM_POINT | VARCHAR (10) | X | The point during the transport of captured data that a transform happens. Support values are EXTRACT or LOAD. | ||
| SOURCE_CATALOG_NAME | VARCHAR (255) | Optional name for the catalog the configured table is in. | |||
| SOURCE_SCHEMA_NAME | VARCHAR (255) | Optional name for the schema a configured table is in. | |||
| SOURCE_TABLE_NAME | VARCHAR (255) | X | The name of the source table that will be transformed. | ||
| TARGET_CATALOG_NAME | VARCHAR (255) | Optional name for the catalog a target table is in. Only use this if the target table is not in the default catalog. | |||
| TARGET_SCHEMA_NAME | VARCHAR (255) | Optional name of the schema a target table is in. Only use this if the target table is not in the default schema. | |||
| TARGET_TABLE_NAME | VARCHAR (255) | The name of the target table. | |||
| UPDATE_FIRST | INTEGER (1) | 0 | If true, the target actions are attempted as updates first, regardless of whether the source operation was an insert or an update. | ||
| DELETE_ACTION | VARCHAR (10) | X | An action to take upon delete of a row. Possible values are: DEL_ROW, UPDATE_COL, or NONE. | ||
| TRANSFORM_ORDER | INTEGER | 1 | X | Specifies the order in which to apply transforms if more than one target operation occurs. | |
| COLUMN_POLICY | VARCHAR (10) | SPECIFIED | X | Specifies whether all columns need to be specified or whether they are implied. Possible values are SPECIFIED or IMPLIED. | |
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. | |||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | Timestamp when a user last updated this entry. |
Table A.36. TRANSFORM_TABLE
Defines the column mappings and optional data transformation for a data loader transformation.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| TRANSFORM_ID | VARCHAR (50) | PK | X | Unique identifier of a specific transform. | |
| INCLUDE_ON | CHAR (1) | * | PK | X | Indicates whether this mapping is included during an insert (I), update (U), delete (D) operation at the target based on the dml type at the source. A value of * represents the fact that you want to map the column for all operations. |
| TARGET_COLUMN_NAME | VARCHAR (128) | PK | X | Name of the target column. | |
| SOURCE_COLUMN_NAME | VARCHAR (128) | Name of the source column. | |||
| PK | INTEGER (1) | 0 | Indicates whether this mapping defines a primary key to be used to identify the target row. At least one row must be defined as a pk for each transform_id. | ||
| TRANSFORM_TYPE | VARCHAR (50) | copy | The name of a specific type of transform. Custom transformers can be configured as extension points. | ||
| TRANSFORM_EXPRESSION | LONGVARCHAR | An expression that is specific to the type of transform that is configured in transform_type. See the documentation for each transformer for more details. | |||
| TRANSFORM_ORDER | INTEGER | 1 | X | Specifies the order in which to apply transforms if more than one target operation occurs. | |
| CREATE_TIME | TIMESTAMP | Timestamp when this entry was created. | |||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | Timestamp when a user last updated this entry. |
Table A.37. TRANSFORM_COLUMN
Configures database triggers that capture changes in the database. Configuration of which triggers are generated for which tables is stored here. Triggers are created in a node's database if the source_node_group_id of a router is mapped to a row in this table.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| TRIGGER_ID | VARCHAR (128) | PK | X | Unique identifier for a trigger. | |
| SOURCE_CATALOG_NAME | VARCHAR (255) | Optional name for the catalog the configured table is in. | |||
| SOURCE_SCHEMA_NAME | VARCHAR (255) | Optional name for the schema a configured table is in. | |||
| SOURCE_TABLE_NAME | VARCHAR (255) | X | The name of the source table that will have a trigger installed to watch for data changes. | ||
| channel_id | VARCHAR (128) | FK | X | The channel_id of the channel that data changes will flow through. | |
| reload_channel_id | VARCHAR (128) | reload | FK | X | The channel_id of the channel that will be used for reloads. |
| SYNC_ON_UPDATE | INTEGER (1) | 1 | X | Whether or not to install an update trigger. | |
| SYNC_ON_INSERT | INTEGER (1) | 1 | X | Whether or not to install an insert trigger. | |
| SYNC_ON_DELETE | INTEGER (1) | 1 | X | Whether or not to install an delete trigger. | |
| SYNC_ON_INCOMING_BATCH | INTEGER (1) | 0 | X | Whether or not an incoming batch that loads data into this table should cause the triggers to capture data_events. Be careful turning this on, because an update loop is possible. | |
| NAME_FOR_UPDATE_TRIGGER | VARCHAR (255) | Override the default generated name for the update trigger. | |||
| NAME_FOR_INSERT_TRIGGER | VARCHAR (255) | Override the default generated name for the insert trigger. | |||
| NAME_FOR_DELETE_TRIGGER | VARCHAR (255) | Override the default generated name for the delete trigger. | |||
| SYNC_ON_UPDATE_CONDITION | LONGVARCHAR | Specify a condition for the update trigger firing using an expression specific to the database. | |||
| SYNC_ON_INSERT_CONDITION | LONGVARCHAR | Specify a condition for the insert trigger firing using an expression specific to the database. | |||
| SYNC_ON_DELETE_CONDITION | LONGVARCHAR | Specify a condition for the delete trigger firing using an expression specific to the database. | |||
| CUSTOM_ON_UPDATE_TEXT | LONGVARCHAR | Specify update trigger text to execute after the SymmetricDS trigger text runs. This field is not applicable for H2, HSQLDB 1.x or Apachy Derby. | |||
| CUSTOM_ON_INSERT_TEXT | LONGVARCHAR | Specify insert trigger text to execute after the SymmetricDS trigger text runs. This field is not applicable for H2, HSQLDB 1.x or Apachy Derby. | |||
| CUSTOM_ON_DELETE_TEXT | LONGVARCHAR | Specify delete trigger text to execute after the SymmetricDS trigger text runs. This field is not applicable for H2, HSQLDB 1.x or Apachy Derby. | |||
| EXTERNAL_SELECT | LONGVARCHAR | Specify a SQL select statement that returns a single result. It will be used in the generated database trigger to populate the EXTERNAL_DATA field on the data table. | |||
| TX_ID_EXPRESSION | LONGVARCHAR | Override the default expression for the transaction identifier that groups the data changes that were committed together. | |||
| CHANNEL_EXPRESSION | LONGVARCHAR | An expression that will be used to capture the channel id in the trigger. This expression will only be used if the channel_id is set to 'dynamic.' | |||
| EXCLUDED_COLUMN_NAMES | LONGVARCHAR | Specify a comma-delimited list of columns that should not be synchronized from this table. Note that if a primary key is found in this list, it will be ignored. | |||
| SYNC_KEY_NAMES | LONGVARCHAR | Specify a comma-delimited list of columns that should be used as the key for synchronization operations. By default, if not specified, then the primary key of the table will be used. | |||
| USE_STREAM_LOBS | INTEGER (1) | 0 | X | Specifies whether to capture lob data as the trigger is firing or to stream lob columns from the source tables using callbacks during extraction. A value of 1 indicates to stream from the source via callback; a value of 0, lob data is captured by the trigger. | |
| USE_CAPTURE_LOBS | INTEGER (1) | 0 | X | Provides a hint as to whether this trigger will capture big lobs data. If set to 1 every effort will be made during data capture in trigger and during data selection for initial load to use lob facilities to extract and store data in the database. On Oracle, this may need to be set to 1 to get around 4k concatenation errors during data capture and during initial load. | |
| USE_CAPTURE_OLD_DATA | INTEGER (1) | 1 | X | Indicates whether this trigger should capture and send the old data (previous state of the row before the change). | |
| USE_HANDLE_KEY_UPDATES | INTEGER (1) | 0 | X | Allows handling of primary key updates (SQLServer dialect only) | |
| CREATE_TIME | TIMESTAMP | X | Timestamp when this entry was created. | ||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. |
Table A.38. TRIGGER
A history of a table's definition and the trigger used to capture data from the table. When a database trigger captures a data change, it references a trigger_hist entry so it is possible to know which columns the data represents. trigger_hist entries are made during the sync trigger process, which runs at each startup, each night in the syncTriggersJob, or any time the syncTriggers() JMX method is manually invoked. A new entry is made when a table definition or a trigger definition is changed, which causes a database trigger to be created or rebuilt.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| TRIGGER_HIST_ID | INTEGER | PK | X | Unique identifier for a trigger_hist entry | |
| TRIGGER_ID | VARCHAR (128) | X | Unique identifier for a trigger | ||
| SOURCE_TABLE_NAME | VARCHAR (255) | X | The name of the source table that will have a trigger installed to watch for data changes. | ||
| SOURCE_CATALOG_NAME | VARCHAR (255) | The catalog name where the source table resides. | |||
| SOURCE_SCHEMA_NAME | VARCHAR (255) | The schema name where the source table resides. | |||
| NAME_FOR_UPDATE_TRIGGER | VARCHAR (255) | The name used when the insert trigger was created. | |||
| NAME_FOR_INSERT_TRIGGER | VARCHAR (255) | The name used when the update trigger was created. | |||
| NAME_FOR_DELETE_TRIGGER | VARCHAR (255) | The name used when the delete trigger was created. | |||
| TABLE_HASH | BIGINT | 0 | X | A hash of the table definition, used to detect changes in the definition. | |
| TRIGGER_ROW_HASH | BIGINT | 0 | X | A hash of the trigger definition. If changes are detected to the values that affect a trigger definition, then the trigger will be regenerated. | |
| TRIGGER_TEMPLATE_HASH | BIGINT | 0 | X | A hash of the trigger text. If changes are detected to the values that affect a trigger text then the trigger will be regenerated. | |
| COLUMN_NAMES | LONGVARCHAR | X | The column names defined on the table. The column names are stored in comma-separated values (CSV) format. | ||
| PK_COLUMN_NAMES | LONGVARCHAR | X | The primary key column names defined on the table. The column names are stored in comma-separated values (CSV) format. | ||
| LAST_TRIGGER_BUILD_REASON | CHAR (1) | X | The following reasons for a change are possible: New trigger that has not been created before (N); Schema changes in the table were detected (S); Configuration changes in Trigger (C); Trigger was missing (T). | ||
| ERROR_MESSAGE | LONGVARCHAR | Record any errors or warnings that occurred when attempting to build the trigger. | |||
| CREATE_TIME | TIMESTAMP | X | Timestamp when this entry was created. | ||
| INACTIVE_TIME | TIMESTAMP | The date and time when a trigger was inactivated. |
Table A.39. TRIGGER_HIST
Map a trigger to a router.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| trigger_id | VARCHAR (128) | PK FK | X | The id of a trigger. | |
| router_id | VARCHAR (50) | PK FK | X | The id of a router. | |
| ENABLED | INTEGER (1) | 1 | X | Indicates whether this trigger router is enabled or not. | |
| INITIAL_LOAD_ORDER | INTEGER | 1 | X | Order sequence of this table when an initial load is sent to a node. If this value is the same for multiple tables, then SymmetricDS will attempt to order the tables according to FK constraints. If this value is set to a negative number, then the table will be excluded from an initial load. | |
| INITIAL_LOAD_SELECT | LONGVARCHAR | Optional expression that can be used to pare down the data selected from a table during the initial load process. | |||
| INITIAL_LOAD_DELETE_STMT | LONGVARCHAR | The expression that is used to delete data when an initial load occurs. If this field is empty, no delete will occur before the initial load. If this field is not empty, the text will be used as a sql statement and executed for the initial load delete. | |||
| INITIAL_LOAD_BATCH_COUNT | INTEGER | 1 | Only applicable if the initial load extract job is enabled. The number of batches to split an initial load of a table across. If 0 then a select count(*) will be used to dynamically determine the number of batches based on the max_batch_size of the reload channel. | ||
| PING_BACK_ENABLED | INTEGER (1) | 0 | X | When enabled, the node will route data that originated from a node back to that node. This attribute is only effective if sync_on_incoming_batch is set to 1. | |
| CREATE_TIME | TIMESTAMP | X | Timestamp when this entry was created. | ||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. |
Table A.40. TRIGGER_ROUTER
This tables defines what grouplets are associated with what trigger routers. The existence of the grouplet for a trigger_router enables nodes associated with the grouplet and at the same time it disables the trigger router for all other nodes.
| Name | Type / Size | Default | PK FK | not null | Description |
|---|---|---|---|---|---|
| grouplet_id | VARCHAR (50) | PK FK | X | Unique identifier for the grouplet. | |
| trigger_id | VARCHAR (128) | PK FK | X | The id of a trigger. | |
| router_id | VARCHAR (50) | PK FK | X | The id of a router. | |
| APPLIES_WHEN | CHAR (1) | PK | X | Indicates the side that a grouplet should be applied to. Use 'T' for target and 'S' for source and 'B' for both source and target. | |
| CREATE_TIME | TIMESTAMP | X | Timestamp when this entry was created. | ||
| LAST_UPDATE_BY | VARCHAR (50) | The user who last updated this entry. | |||
| LAST_UPDATE_TIME | TIMESTAMP | X | Timestamp when a user last updated this entry. |
Table A.41. TRIGGER_ROUTER_GROUPLET