This User Guide will introduce both basic and advanced concepts in the configuration of SymmetricDS. By the end of this chapter, you will have a better understanding of SymmetricDS' capabilities, and many of its basic concepts.
SymmetricDS is written in Java and requires a Java SE Runtime Environment (JRE) or Java SE Development Kit (JDK) version 6.0 or above.
Any database with trigger technology and a JDBC driver has the potential to run SymmetricDS. The database is abstracted through a Database Dialect in order to support specific features of each database. The following Database Dialects have been included with this release:
MySQL version 5.0.2 and above
MariaDB version 5.1 and above
Oracle version 10g and above
PostgreSQL version 8.2.5 and above
Sql Server 2005 and above
Sql Server Azure
HSQLDB 2.x
H2 1.x
Apache Derby 10.3.2.1 and above
IBM DB2 9.5
Firebird 2.0 and above
Interbase 2009 and above
Greenplum 8.2.15 and above
SQLite 3 and above
Sybase Adaptive Server Enterprise 12.5 and above
Sybase SQL Anywhere 9 and above
See Appendix C, Database Notes, for compatibility notes and other details for your specific database.
SymmetricDS is a Java-based application that hosts a synchronization engine which acts as an agent for data synchronization between a single database instance and other synchronization engines in a network.
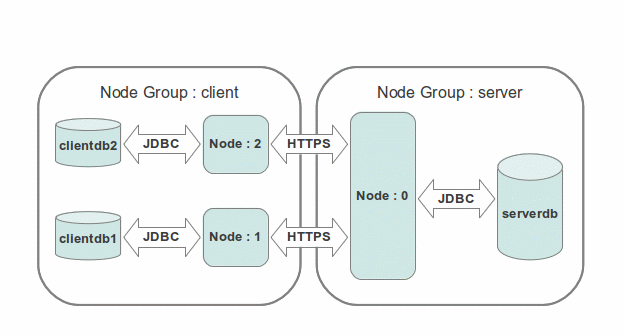
The SymmetricDS engine is referred to as a node. SymmetricDS is designed to be able to scale out to many thousands of nodes. The database connection is configured by providing a database connection string, database user, and database password in a properties file. SymmetricDS can synchronize any table that is accessible by the database connection, given that the database user has been assigned the appropriate database permissions.
A SymmetricDS node is assigned an external id and a node group id. The external id is a meaningful, user-assigned identifier that is used by SymmetricDS to understand which data is destined for a given node. The node group id is used to identify groupings or tiers of nodes. It defines where the node fits into the overall node network. For example, one node group might be named “corporate” and represent an enterprise or corporate database. Another node group might be named “local_office” and represent databases located in different offices across a country. The external id for a “local_office” could be an office number or some other identifying alphanumeric string. A node is uniquely identified in a network by a node id that is automatically generated from the external id. If local office number 1 had two office databases and two SymmetricDS nodes, they would probably have an external id of “1” and node ids of “1-1” and “1-2.”
SymmetricDS can be deployed in a number of ways. The most common option is to deploy it as a stand alone process running as a service on your chosen server platform. When deployed in this manner SymmetricDS can act as either a client, a multi-tenant server or both depending on where the SymmetricDS database fits into the overall network of databases. Although it can run on the same server as its database, it is not required to do so. SymmetricDS can also be deployed as a web application in an application server such as Apache Tomcat, JBoss Application Server, IBM WebSphere, or others.
SymmetricDS was designed to be a simple, approachable, non-threatening tool for technology personnel. It can be thought of and dealt with as a web application, only instead of a browser as the client, other SymmetricDS engines are the clients. It has all the characteristics of a web application and can be tuned using the same principles that would be used to tune user facing web applications.
Changes are captured at a SymmetricDS enabled database by database triggers that are installed automatically by SymmetricDS based on configuration settings that you specify. The database triggers record data changes in the DATA table. The triggers are designed to be as noninvasive and as lightweight as possible. After SymmetricDS triggers are installed, changes are captured for any Data Manipulation Language (DML) statements performed by external applications. Note that no additional libraries or changes are needed by the applications that use the database and SymmetricDS does not have to be online for data to be captured.
Database tables that need to be replicated are configured in a series of SymmetricDS configuration tables. The configuration for the entire network of nodes is typically managed at a central node in the network, known as the registration server node. The registration server node is almost always the same node as the root node in a tree topology. When configuring “leaf” nodes, one of the start-up parameters is the URL of the registration server node. If the “leaf” node has not yet registered, it contacts the registration server and requests to join the network. Upon acceptance, the node downloads its configuration. After a node is registered, SymmetricDS can also provide an initial load of data before synchronization starts.
SymmetricDS will install or update its database triggers at start-up time and on a regular basis when a scheduled sync triggers job runs (by default, each night at midnight). The sync triggers job detects changes to your database structure or trigger configuration when deciding whether a trigger needs to be rebuilt. Optionally, the sync triggers job can be turned off and the database triggers DDL script can be generated and run by a DBA.
After changed data is inserted by the database trigger into the DATA table, it is batched and assigned to a node by the router job. Routing data refers to choosing the nodes in the SymmetricDS network to which the data should be sent. By default, data is routed to other nodes based on the node group. Optionally, characteristics of the data or of the target nodes can also be used for routing. A batch of data is a group of data changes that are transported and loaded together at the target node in a single database transaction. Batches are recorded in the OUTGOING_BATCH . Batches are node specific. DATA and OUTGOING_BATCH are linked by DATA_EVENT . The delivery status of a batch is maintained in OUTGOING_BATCH . After the data has been delivered to a remote node the batch status is changed to ‘OK.’
Data is delivered to remote nodes over HTTP or HTTPS. It can be delivered in one of two ways depending on the type of transport link that is configured between node groups. A node group can be configured to push changes to other nodes in a group or pull changes from other nodes in a group. Pushing is initiated from the push job at the source node. If there are batches that are waiting to be transported, the pushing node will reserve a connection to each target node using an HTTP HEAD request. If the reservation request is accepted, then the source node will fully extract the data for the batch. Data is extracted to a memory buffer in CSV format until a configurable threshold is reached. If the threshold is reached, the data is flushed to a file and the extraction of data continues to that file. After the batch has been extracted, it is transported using an HTTP PUT to the target node. The next batch is then extracted and sent. This is repeated until the maximum number of batches have been sent for each channel or there are no more batches available to send. After all the batches have been sent for one push, the target returns a list of the batch statuses.
Pull requests are initiated by the pull job from at the target node. A pull request uses an HTTP GET. The same extraction process that happens for a "push" also happens during a "pull."
After data has been extracted and transported, the data is loaded at the target node. Similar to the extract process, while data is being received the data loader will cache the CSV in a memory buffer until a threshold is reached. If the threshold is reached the data is flushed to a file and the receiving of data continues. After all of the data in a batch is available locally, a database connection is retrieved from the connection pool and the events that had occurred at the source database are played back against the target database.
Data is always delivered to a remote node in the order it was recorded for a specific channel. A channel is a user defined grouping of tables that are dependent on each other. Data that is captured for tables belonging to a channel is always synchronized together. Each trigger must be assigned a channel id as part of the trigger definition process. The channel id is recorded on SYM_DATA and SYM_OUTGOING_BATCH. If a batch fails to load, then no more data is sent for that channel until the failure has been addressed. Data on other channels will continue to be synchronized, however.
If a remote node is offline, the data remains recorded at the source database until the node comes back online. Optionally, a timeout can be set where a node is removed from the network. Change data is purged from the data capture tables by SymmetricDS after it has been sent and a configurable purge retention period has been reached. Unsent change data for a disabled node is also purged.
The default behavior of SymmetricDS in the case of data integrity errors is to attempt to repair the data. If an insert statement is run and there is already a row that exists, SymmetricDS will fall back and try to update the existing row. Likewise, if an update that was successful on a source node is run and no rows are found to update on the destination, then SymmetricDS will fall back to an insert on the destination. If a delete is run and no rows were deleted, the condition is simply logged. This behavior can be modified by tweaking the settings for conflict detection and resolution.
SymmetricDS was designed to use standard web technologies so it can be scaled to many clients across different types of databases. It can synchronize data to and from as many client nodes as the deployed database and web infrastructure will support. When a two-tier database and web infrastructure is maxed out, a SymmetricDS network can be designed to use N-tiers to allow for even greater scalability. At this point we have covered what SymmetricDS is and how it does its job of replicating data to many databases using standard, well understood technologies.
At a high level, SymmetricDS comes with a number of features that you are likely to need or want when doing data synchronization. A majority of these features were created as a direct result of real-world use of SymmetricDS in production settings.
In practice, much of the data in a typical synchronization requires synchronization in just one direction. For example, a retail store sends its sales transactions to a central office, and the central office sends its stock items and pricing to the store. Other data may synchronize in both directions. For example, the retail store sends the central office an inventory document, and the central office updates the document status, which is then sent back to the store. SymmetricDS supports bi-directional or two-way table synchronization and avoids getting into update loops by only recording data changes outside of synchronization.
SymmetricDS supports the concept of channels of data. Data synchronization is defined at the table (or table subset) level, and each managed table can be assigned to a channel that helps control the flow of data. A channel is a category of data that can be enabled, prioritized and synchronized independently of other channels. For example, in a retail environment, users may be waiting for inventory documents to update while a promotional sale event updates a large number of items. If processed in order, the item updates would delay the inventory updates even though the data is unrelated. By assigning changes to the item tables to an item channel and inventory tables' changes to an inventory channel, the changes are processed independently so inventory can get through despite the large amount of item data.
Channels are discussed in more detail in Section 3.3, “Channels” .After a change to the database is recorded, the SymmetricDS nodes interested in the change are notified. Change notification is configured to perform either a push (trickle-back) or a pull (trickle-poll) of data. When several nodes target their changes to a central node, it is efficient to push the changes instead of waiting for the central node to pull from each source node. If the network configuration protects a node with a firewall, a pull configuration could allow the node to receive data changes that might otherwise be blocked using push. The frequency of the change notification is configurable and defaults to once per minute.
By default, SymmetricDS uses web-based HTTP or HTTPS in a style
called Representation State Transfer (REST). It is lightweight and easy
to manage. A series of filters are also provided to enforce
authentication and to restrict the number of simultaneous
synchronization streams. The ITransportManager
interface allows other transports to be implemented.
Using SymmetricDS, data can be filtered as it is recorded, extracted, and loaded.
Data routing is accomplished by assigning a router type to a
ROUTER configuration.
Routers are responsible for identifying what target nodes captured
changes should be delivered to. Custom routers are possible by
providing a class implementing IDataRouter
.
In addition to synchronization, SymmetricDS is also capable of performing fairly complex transformations (see Section 3.8 ) of data as the synchronization data is loaded into a target database. The transformations can be used to merge source data, make multiple copies of source data across multiple target tables, set defaults in the target tables, etc. The types of transformation can also be extended to create even more custom transformations.
As data changes are loaded in the target database, data can be filtered, either by a simple bean shell load filter (see Section 3.9 data-load-filter) or by a class implementing IDatabaseWriterFilter. You can change the data in a column, route it somewhere else, trigger initial loads, or many other possibilities. One possible use might be to route credit card data to a secure database and blank it out as it loads into a centralized sales database. The filter can also prevent data from reaching the database altogether, effectively replacing the default data loading process.
Many databases provide a unique transaction identifier associated with the rows that are committed together as a transaction. SymmetricDS stores the transaction identifier, along with the data that changed, so it can play back the transaction exactly as it occurred originally. This means the target database maintains the same transactional integrity as its source. Support for transaction identification for supported databases is documented in the appendix of this guide.
Administration functions are exposed through Java Management Extensions (JMX) and can be accessed from the Java JConsole or through an application server. Functions include opening registration, reloading data, purging old data, and viewing batches. A number of configuration and runtime properties are available to be viewed as well.
SymmetricDS also provides functionality to send SQL events through the same synchronization mechanism that is used to send data. The data payload can be any SQL statement. The event is processed and acknowledged just like any other event type.
Quite a few users of SymmetricDS have found that they have a need to not only synchronize database tables to remote locations, but they also have a set of files that should be synchronized. As of version 3.5 SymmetricDS now support file synchronization.
Please see Section 3.5, “File Triggers / File Synchronization” for more information.
There are several industry recognized techniques to capture changing data for replication, synchronization and integration in a relational database.
Lazy data capture queries changed data from a source system using some SQL condition (like a time stamp column).
Trigger-based data capture installs database triggers to capture changes.
Log-based data capture reads data changes from proprietary database recovery logs.
All three of these techniques have advantages and disadvantages, and all three are on the road map for SymmetricDS. At present time, SymmetricDS supports trigger-based data capture and partial lazy data capture. These two techniques were implemented first for a variety of reasons, not the least of which is that the majority of use cases that SymmetricDS targets can be solved using trigger-based and conditional replication in a way that allows for more database platforms to be supported using industry standard technologies. This fact allowed SymmetricDS developers' valuable time and energy to be invested in designing a product that is easy to install, configure and manage versus spending time reverse engineering proprietary and not well documented database log files.
Trigger-based data capture does introduce a measurable amount of overhead on database operations. The amount of overhead can vary greatly depending on the processing power and configuration of the database platform, and the usage of the database by applications. With nonstop advances in hardware and database technology, trigger-based data capture has become feasible for use cases that involve high data throughput or require scaling out.
Trigger-based data capture is easier to implement and support than log-based solutions. It uses well known database concepts and is very accessible to software and database developers and database administrators. It can usually be installed, configured, and managed by application development teams or database administrators and does not require deployment on the database server itself.